March 25th, 2026
How to Automate SEO Outlines in 2026: A Guide to AI Content Brief Generators
 WD
WDWarren Day
Your organic click-through rate just dropped 61% -- not because your rankings slipped, but because a Google AI Overview answered the query before anyone reached your result. When AI Overviews appear, CTR collapses from 1.76% to 0.61%. And they're showing up across more queries every month.
If you're still building content around the assumption that ranking means traffic, that assumption is broken.
Here's the compounding problem: your briefing process hasn't kept pace. You're still manually pulling SERP data, reverse-engineering competitor structures, assembling everything in a Google Doc -- burning three to five hours per piece before a single word gets written. That bottleneck is exactly why content velocity stalls the moment demand picks up.
The answer isn't a shinier AI writing tool. Frase, Jasper, and Surfer are useful, but they're point solutions. What actually moves the needle in 2026 is treating your AI content brief generator as a system -- an automated, event-driven pipeline that pulls live SERP data, runs competitive analysis, and applies citation engineering before your writer opens a blank document.
Competitive advantage no longer comes from which tool you pick. It comes from engineering a pipeline that connects SERP API integration, a vector knowledge layer, and your CMS into a single automated workflow -- one that produces briefs optimized for both traditional rankings and AI Overview citations.
What follows is a practical blueprint for building that pipeline, including two concrete tech stacks you can implement based on your team's resources and technical depth.
Beyond the Tool: Why 2026 Demands an AI Content Brief Generator Pipeline
The content brief hasn't changed. Your workflow around it has to.
AI Overviews now reach 2 billion monthly users, and zero-click behavior is only accelerating. Ranking on page one no longer guarantees a click -- it barely guarantees visibility. The teams winning in this environment aren't just using smarter tools. They've rebuilt how briefs get created from the ground up.
The problem with the current approach isn't effort. It's architecture. Most content teams still operate in silos: pull keywords from Ahrefs, check SERPs manually, copy competitor headings into a doc, paste it into ChatGPT, and hope the output is usable. Every step is a handoff. Every handoff is a point of failure.
An AI content brief generator pipeline is an automated, event-driven system that transforms a seed keyword into a structured, data-rich, CMS-ready brief by connecting live SERP data, competitive analysis, and AI synthesis into a single continuous workflow -- without manual intervention between steps.
That's the operational shift this article is about. Not which tool to buy. Which system to build.
The teams that have already made this shift aren't debating which AI writing assistant has the best UI. They're running briefs in minutes that used to take half a workday -- and the output is richer because nothing gets lost between tabs.
Blueprint: The Anatomy of an Automated Brief Generation Pipeline
Before you build anything, you need a clear mental model of what you're actually building. Not a tool. A pipeline -- a sequence of connected systems where data flows in one end and a publish-ready brief comes out the other.
Here's the architecture:
[Keyword / Topic Trigger]
↓
[SERP & AI Overview Data Fetcher] ← SERP API (SerpApi, DataForSEO, SerpWow)
↓
[Analysis & Knowledge Layer] ← Vector DB (Pinecone/Weaviate) + RAG
↓
[Brief Orchestrator] ← AI model + rules engine (n8n / Make)
↓
[CMS Integration] ← Sanity, Contentful, WordPress, Webflow
↓
[Human-in-the-Loop Gate] ← Editor review + approval
↓
[Publish + Audit Log]
Each node has a distinct job. The SERP API is your data input layer -- it pulls live rankings, People Also Ask boxes, and AI Overview snapshots for your target keyword. The vector database is the brain: it stores embeddings of your existing content, competitor pages, and citation candidates, enabling semantic retrieval rather than keyword matching. The orchestrator (typically n8n or Make) is the nervous system that sequences every step, passes data between nodes, and enforces your rules. The CMS integration is the output layer -- briefs land directly in your content workspace, not in someone's inbox. And the human checkpoint is where editorial judgment enters before anything goes live.
This pattern isn't theoretical. Sanity's recommended AI integration model follows exactly this sequence: trigger on content event, run AI analysis, patch the document, log for auditing. That four-step loop is the backbone of every well-engineered pipeline.
What separates this from a manual process isn't just speed. It's the event-driven nature of the whole thing. A new keyword enters your tracking sheet and the entire pipeline fires automatically. No tab-switching. No copy-pasting. No brief sitting in a queue for three days waiting for someone to get to it.
The next three sections break down the core components: data ingestion, the knowledge layer, and orchestration. Each one is a decision point where your ai content brief generator pipeline either compounds your competitive advantage -- or leaks it.
Core Component 1: Feeding the Pipeline with Live SERP & AI Overview Data
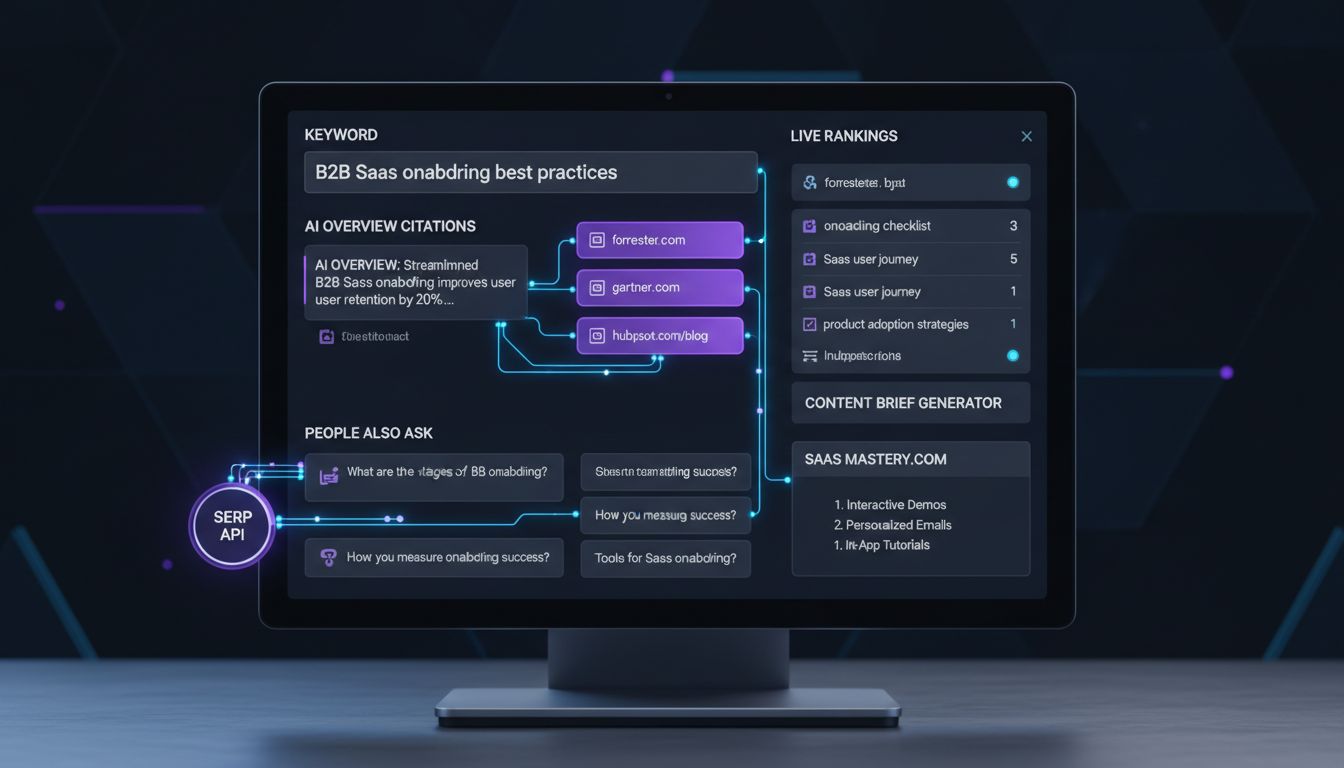
Your pipeline is only as good as its inputs.
Stale data produces stale briefs. Yesterday's rankings, last week's AI Overview snapshot -- by the time a writer opens the brief, it's already wrong. And with Google's AI Overviews shifting which sources get cited on a query-by-query basis, "close enough" isn't close enough. You need a data layer that reflects the SERP right now.
Why "Weekly Crawl" Thinking Breaks Here
Traditional rank trackers batch their data collection. That's fine for reporting. It's fatal for brief generation.
The SERP features that matter most for citation engineering -- AI Overviews, People Also Ask clusters, featured snippets -- can rotate within hours of a news event or algorithm update. Your brief needs to capture what's actually appearing today for your target query, not what was appearing when the crawler last swung by.
What Your SERP API Must Actually Capture
Before comparing vendors, get clear on the data types you need to extract for each target keyword:
- AI Overview content and source URLs -- the verbatim text blocks and the 6-7 pages on average that Google cites inside them
- Organic top-10 URLs, titles, and meta descriptions -- for structural and topical pattern analysis
- People Also Ask questions -- direct inputs to your brief's "questions to answer" section
- Featured snippets and Knowledge Panel data -- signals on what format Google rewards
- SERP feature presence -- whether video carousels, local packs, or image blocks are displacing organic links
This structured output -- not raw HTML -- is what feeds your knowledge layer in the next stage.
SERP API Provider Comparison (As of 2026)
| Provider | AI Overview Support | Speed | Cost per 1,000 Requests | Best For |
|---|---|---|---|---|
| SerpApi | ✅ Dedicated AI Overview API + AI Mode API | ~1.2s | ~$15 | Developer-first; richest feature set |
| DataForSEO | ✅ load_async_ai_overview parameter |
~2.0s | ~$1.20 | High-volume SEO platforms; pay-as-you-go |
| SerpWow | ✅ include_ai_overview=true parameter |
~2.5s | ~$1.60 | Straightforward integration; 100k+ locations |
| Serpex.dev | ✅ AI SEO-focused | ~2.5s | ~$0.30 | Budget-conscious pipelines |
| Bright Data / Apify | ⚠️ Via proxy infrastructure | Varies | Varies | Enterprise scale; existing proxy users |
Vendor-reported figures; verify current pricing before committing.
Controlling Costs Without Sacrificing Freshness
Google AI Overview API calls aren't free, and at scale they add up fast.
Cache strategically. SerpApi's ai_overview.page_token expires within one minute -- meaning you can't cache the token itself, but you can cache the full structured response for stable informational queries. Refresh high-velocity commercial queries daily; evergreen topics weekly.
Sample intelligently. Not every keyword in your pipeline needs a full AI Overview pull. Trigger live Google AI Overview scraping only when a keyword clears your volume or difficulty threshold, or when a content update is actually scheduled. Pulling fresh data on keywords you won't touch for six months is just burning budget.
The output of this layer -- a structured JSON object containing ranked URLs, heading patterns, PAA questions, AI Overview text blocks, and cited sources -- becomes the raw material for your vector database in the next component.
Core Component 2: The Analysis & Knowledge Layer (Vector DB + RAG)
Here's the uncomfortable truth about raw LLMs: ask GPT-4 to write a content brief for "B2B SaaS onboarding best practices" and you'll get something that looks complete but is built entirely from its training data -- frozen in time, ignorant of your niche, and almost certainly trained on your competitors' content too. The output is generic because the input is generic.
This is the grounding problem. It's also the main reason your team is skeptical every time someone mentions an ai content brief generator.
The fix is Retrieval-Augmented Generation (RAG). Instead of sending your seed keyword straight to an LLM and hoping for the best, you first query a knowledge base of real, curated content -- then pass that context to the model. The LLM isn't guessing anymore. It's synthesizing from evidence you've hand-selected.
Building Your Knowledge Base
Your vector database is that knowledge base. You populate it with content embeddings -- numerical representations of text that capture semantic meaning -- from three sources:
- Top-ranking SERP pages (the structured JSON from Component 1)
- Your own best-performing content (posts that already rank or convert)
- Authoritative third-party sources relevant to your topic cluster
When a new keyword enters the pipeline, the system queries the vector database for semantically similar content patterns -- not exact keyword matches, but conceptually related chunks. Those retrieved chunks get injected into the LLM prompt as context, producing a brief grounded in what actually works in your space.
Choosing Your Vector DB
Benchmarks across Pinecone, Weaviate, and Chroma point to three distinct use cases:
- Pinecone -- Fully managed, serverless, sub-50ms query latency. Best for teams who want zero infrastructure overhead and are ready for production from day one.
- Weaviate -- Hybrid keyword + vector search, flexible self-hosting. Best when you need deployment control or your queries mix semantic and exact-match needs.
- Chroma -- Local-first, Python-native, zero setup. Best for prototyping your pipeline before committing to infrastructure costs.
Start with Chroma to validate your RAG logic. Graduate to Pinecone or Weaviate when you're processing more than a handful of briefs per day.
What Comes Out
The RAG layer doesn't write the brief -- it assembles the context for the next stage.
What you get is an enriched prompt bundle: your seed keyword, retrieved heading patterns and content structures from top-performing pages, PAA questions, and AI Overview citations. That bundle goes to the orchestrator with enough grounding that the LLM has no excuse for producing something generic.
This is also where content engineering becomes a structural advantage. Content with clear hierarchy and explicit semantic coverage consistently outperforms across both traditional rankings and AI citation surfaces -- and your RAG layer enforces that structure from the brief stage, before a single word of the article is written. Not after a writer has already gone sideways. Before.
Core Component 3: Orchestration, Integration & Brief Assembly
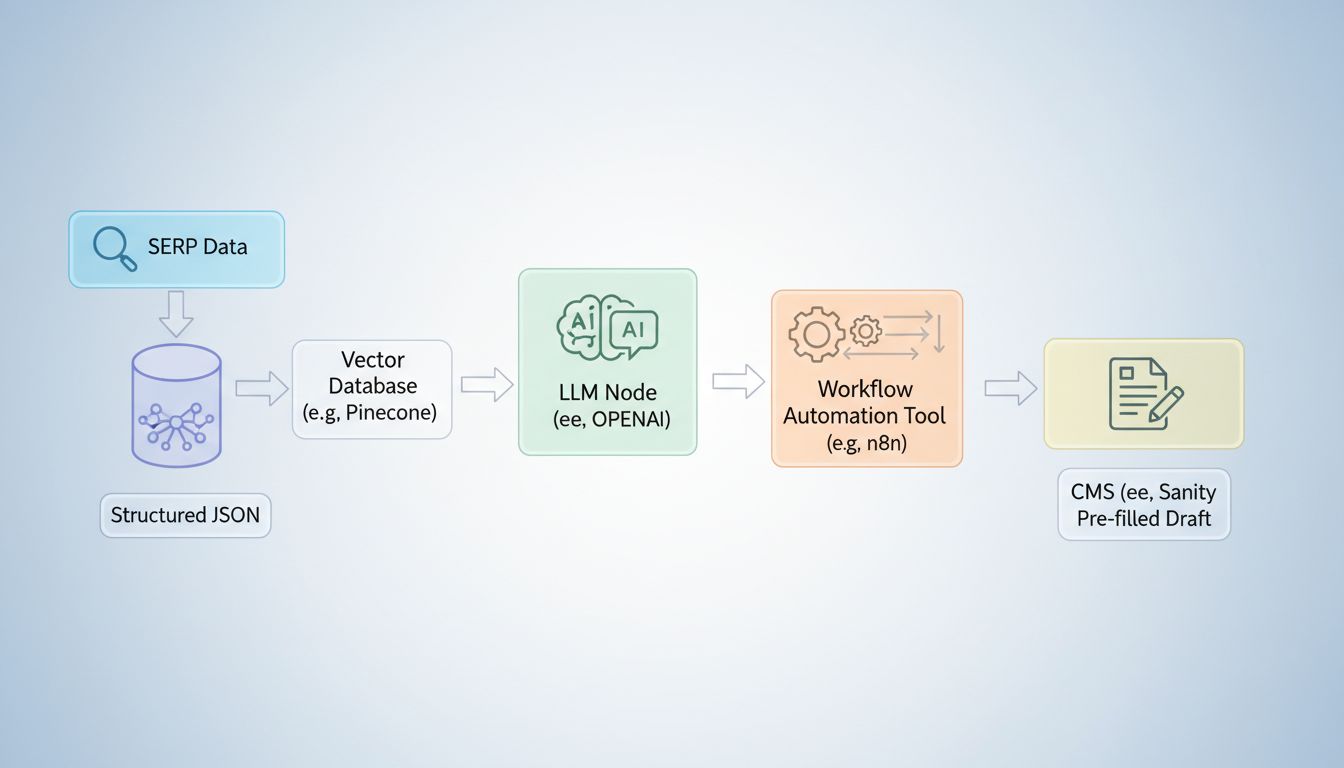
Your SERP data is collected. Your vector layer has retrieved the right competitive context. Now you need something to conduct all of it -- sequencing the steps, passing data between nodes, and depositing a finished brief directly into your CMS. That conductor is your workflow automation layer.
n8n is the right tool for this job if your team has any technical capacity. It has native nodes for RAG pipelines, vector databases, AI models, and CMS integrations -- all in a single visual canvas. Zapier and Make work for simpler setups or non-technical teams, but they'll hit limits fast once you're chaining five or more steps with conditional logic.
A Concrete n8n Workflow, Node by Node
Here's what a production brief-generation workflow actually looks like:
- Webhook Trigger -- A new keyword (or approved topic from your editorial calendar) fires an HTTP POST to your n8n instance. This is your event. Everything downstream is deterministic from this point.
- SerpApi Node (HTTP Request) -- Calls the SerpApi endpoint with your keyword, returning the top-10 organic results, People Also Ask data, and the current AI Overview snapshot if one exists.
- Pinecone Query Node -- Embeds the keyword and queries your vector store for semantically similar documents already in your knowledge base -- your past content, competitor summaries, and authoritative sources ingested earlier.
- OpenAI Node (Structured Prompt) -- Receives the SERP data + retrieved context and runs a structured prompt. Critically, this prompt is not "write me a brief." It specifies output fields: target intent, competitive gaps, suggested H2/H3 structure, citation-worthy facts, internal link targets, meta description variants. The output is a JSON object, not a text blob.
- Sanity Create Draft Node -- Pushes the structured JSON directly into Sanity as a new draft document, pre-populated with all brief fields. Sanity's recommended trigger → analyze → patch → log pattern means every AI-generated field is stamped with metadata -- who triggered it, when, and what model version ran.
For WordPress teams, SEOPress PRO's OpenAI integration handles the meta-tag and title-suggestion layer natively, so your n8n workflow can push the structural brief via REST API while SEOPress handles on-page metadata on the other end.
The Brief as a Structured Data Object
Most teams miss this entirely. A good auto-generated brief isn't a Google Doc with bullet points -- it's a structured record with discrete, queryable fields:
| Field | Purpose |
|---|---|
target_intent |
Informational / commercial / transactional classification |
competitive_gaps |
Topics covered by top-3 competitors but absent from your existing content |
h2_h3_structure |
Suggested heading hierarchy with estimated word counts per section |
citation_worthy_facts |
Sourced statistics and claims to embed for AI citability |
internal_link_targets |
Existing URLs from your site mapped to relevant sections |
external_authority_sources |
Third-party URLs your RAG layer flagged as high-citation candidates |
meta_description_options |
Two or three variants for A/B testing |
When the brief lives as structured data in your CMS, your writers open a document that's already half-built. Research is done. Architecture is set. Their job becomes judgment and voice -- not retrieval.
That shift is what separates a functional ai content brief generator from a glorified text expander. The former hands writers a scaffold; the latter hands them more work dressed up as help.
The prompt engineering that feeds the OpenAI node matters here too. Prompting with job-title + pain points (e.g., "You are writing for a VP of Marketing at a 50-person SaaS company struggling with content velocity") consistently produces more targeted gap analysis than generic prompts. That persona layer belongs in the system prompt -- not left to the writer to reconstruct each time they sit down.
Governance: Building Effective Human-in-the-Loop Checkpoints
Automation doesn't eliminate judgment -- it concentrates it. Your pipeline can generate a brief in minutes, but without structured checkpoints, you're one hallucinated statistic away from publishing something that damages your brand's credibility or gets flagged by Google's quality systems.
The question isn't whether to review AI-generated content before publishing -- of course you should. The question is where in your pipeline that review happens, and how you make it systematic rather than something a junior editor does differently every time.
The Three Non-Negotiable Checkpoints
Checkpoint 1: Editorial Review -- after brief generation, before writer assignment. This is your highest-leverage moment. A content strategist or senior editor should spend 10-15 minutes validating the brief's strategic angle, confirming the primary keyword intent is correct, and checking that the suggested sources are authoritative. The AI will miss nuance around your product positioning every time. That's not a bug -- it's the gap your expertise fills.
Checkpoint 2: Automated Originality Scan -- before CMS submission. Integrate the Copyscape API directly into your n8n workflow as a pre-publish node. It runs automatically, requires zero human time, and catches any passages where the AI has leaned too heavily on a source's phrasing. Automating this check removes a real concern without slowing your team down at all.
Checkpoint 3: Audit Logging -- at every AI-generated patch. Log every AI suggestion, every structured output, and every brief modification with a timestamp and model version. Without this, you have no traceability, no way to tune your prompts over time, and no defense if an output causes a problem downstream. Sanity's recommended trigger → analyze → patch → log pattern exists for exactly this reason.
Using n8n's Built-In AI Governance Tools
n8n's Guardrails nodes (introduced in version 1.119) run in two modes: Check flags policy violations before content moves forward; Sanitize automatically redacts or rewrites problematic text. Add a Guardrails node immediately after your OpenAI analysis step to enforce rules like: no unverified statistics, no competitor mentions, no PII in brief outputs.
The Model Context Protocol (MCP) node adds a second layer. It gives your AI agent structured context about what it's allowed to do at each workflow stage, preventing scope creep where the model starts making decisions it wasn't designed to make.
Honestly, AI governance isn't bureaucracy. It's the mechanism that makes your ai content brief generator trustworthy enough to actually scale -- and the thing that lets you hand writers a scaffold they can actually trust rather than one they have to fact-check from scratch.
Two Practical Implementation Stacks for 2026
Architectural patterns are only useful if you can actually build them. Below are two concrete blueprints: one for teams who live in no-code tools, one for teams who want full control. The specific tools and pricing will shift. The underlying logic won't.
Choose based on honest self-assessment. If your team has no developer resources, start with Stack 1. If you have engineering support or a technically fluent ops person, Stack 2 gives you a system that scales without hitting ceilings.
Stack 1: The Low-Code Marketer's Pipeline
Goal: Ship a working brief generator in a weekend, without writing code.
Core tools: Make (Integromat) + Surfer SEO + WordPress or Webflow
The data layer here is battle-tested. Surfer users have seen a 423% average uplift in organic and AI visibility, with pages updated via Surfer twice as likely to reach the Top 10 within 30 days.
Steps:
- Trigger , A new row is added to a Google Sheet (keyword, target URL, priority tier).
- Fetch metrics , Make calls the Surfer SEO API to pull NLP terms, competitor word counts, and content score benchmarks for that keyword.
- Generate outline , Pass the Surfer data plus a structured prompt to OpenAI via Make's HTTP module; return a JSON outline with H2s, H3s, and suggested word counts per section.
- Populate brief template , Make maps the JSON fields into a Google Doc or Notion template (title, intent, outline, NLP terms, internal link targets, CTA guidance).
- Create draft , A Make webhook pushes the brief as a draft post into WordPress or Webflow, with metadata fields pre-filled.
- Notify reviewer , A Slack message fires with a direct link to the draft for human sign-off before the brief is actioned.
Realistic build time: 4–8 hours for someone comfortable with Make.
Stack 2: The Scalable Developer's Pipeline
Goal: Full control over data, custom analytics, and a system that handles hundreds of briefs per week without breaking.
Core tools: n8n + SerpApi + Pinecone + OpenAI or Gemini + Sanity CMS
Steps:
- Scheduled trigger , n8n fires on a cron job, pulling a keyword batch from your database or Airtable.
- Live SERP fetch , SerpApi returns SERP features, People Also Ask, and the current AI Overview snapshot for each keyword.
- Vector similarity query , Pinecone is queried for your top-performing existing content on semantically related topics; results surface proven structural patterns.
- Prompt assembly , n8n combines SERP data, Pinecone results, and your brand guidelines into a structured context block.
- Brief generation , OpenAI or Gemini returns a structured JSON brief: intent classification, recommended headings, citation targets, NLP terms, and a suggested internal link map.
- Sanity CMS push , n8n creates a Sanity document, patches it with AI-generated metadata, and logs the generation event for auditing.
- Human checkpoint , The brief sits in a "Pending Review" status in Sanity until an editor approves it, triggering the writer assignment workflow.
Realistic build time: 2–5 days for a developer familiar with n8n automation and REST APIs.
The low-code stack gets you moving fast. The developer stack gets you somewhere worth going at scale.
Most teams start with Stack 1, hit its limits around brief volume or customization, then migrate the architecture to Stack 2. Not the logic. Just the plumbing. That's actually the right order of operations: prove your ai content brief generator works before you invest in making it bulletproof.
Measuring Success: From Traditional Rankings to AI Citations & ROI
Most teams building this pipeline will face the same internal question within 90 days: is this actually working? The honest answer is that you won't know if you're measuring the wrong things , and most teams still are.
Rank tracking alone is a rearview mirror. You need a four-tier measurement framework.
Tier 1: AI Visibility Metrics (Your Leading Indicators)
These are the metrics that predict revenue before it shows up in your analytics.
- Citation frequency: How often your content is explicitly cited in AI Overviews, ChatGPT, Perplexity, and Gemini responses for your target queries. LLMs cite only 2-7 domains per response -- far fewer than Google's ten blue links. Either you're in the window or you're not.
- AI Share of Voice (SoV): Your citation frequency relative to competitors across a defined query set. This is the AEO equivalent of rank position.
- Recommendation sentiment: Whether AI responses frame your brand positively, neutrally, or negatively. Tools like Profound track this on a -1 to +1 scale.
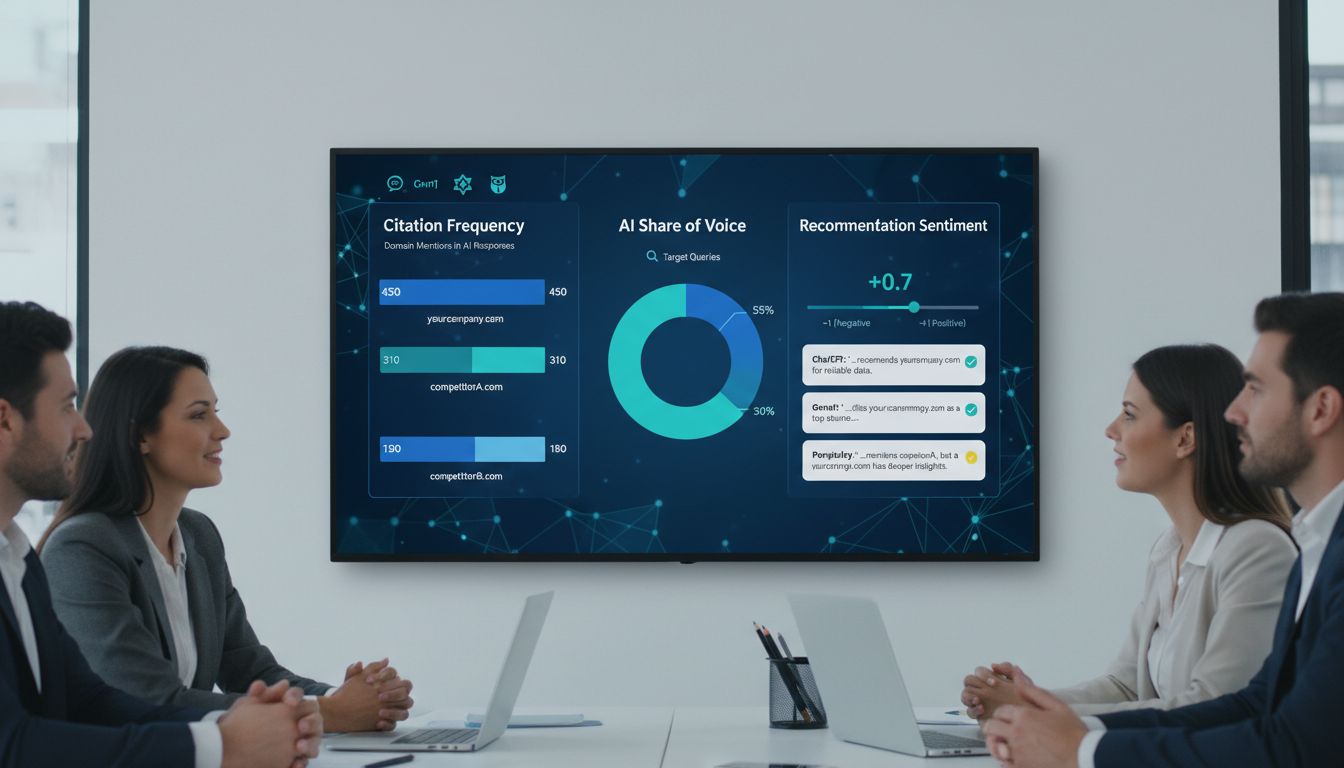
Track these with Semrush's AI visibility module, Ahrefs Brand Radar, or dedicated AEO platforms like Profound or Nozzle. For a no-cost baseline, run your top 20 target queries manually in ChatGPT and Google AI Mode monthly and log the results in a spreadsheet. Not glamorous, but it works.
Tier 2: Business Impact Metrics (Your Lagging Proof)
Here's where you justify the pipeline to leadership.
AI-referred traffic converts at dramatically higher rates than standard organic search, which means even modest citation volume carries serious revenue weight. The math changes fast once you're being cited consistently.
In GA4, filter referral traffic by source: chat.openai.com, perplexity.ai, gemini.google.com. Conversion rate and revenue-per-session from these sources is your clearest signal that AI citations are actually translating to pipeline. If those numbers look good, you have your story.
Tier 3: Traditional SEO Metrics (Still Relevant, No Longer Primary)
Organic impressions, clicks, rankings, and CTR still matter -- especially for queries where AI Overviews don't trigger. Track them. Just don't let them dominate your reporting narrative when the whole landscape is shifting underneath them.
Tier 4: Pipeline Health Metrics
These keep the system honest: cost per brief generated, SERP API latency, human review time per brief, and plagiarism flag rate via Copyscape. If cost per brief creeps above your editorial budget threshold or review time balloons, something upstream broke.
Look at these regularly. They're easy to ignore until they're a real problem.
The most common mistake: only measuring Tiers 3 and 4, then concluding the pipeline "isn't working" because organic traffic didn't spike. AI citation is a leading indicator -- it precedes the traffic, not the other way around. Teams that don't understand that sequencing end up killing good systems too early.
Common Pitfalls That Break Your Automation (And How to Avoid Them)
Building the pipeline is the hard part. Breaking it is surprisingly easy.
Here are the six anti-patterns most teams hit, and the fixes that are already baked into the architecture described in this article.
1. Skipping the Human Review Gate The vast majority of marketers review AI-generated content before publishing, and for good reason. Automating past the editorial checkpoint doesn't save time, it creates brand liability. Keep the approval node in your n8n workflow. Non-negotiable.
2. Feeding the Pipeline Stale SERP Data A brief built on three-month-old SERP snapshots is a brief built on a lie. SERP data freshness isn't a nice-to-have, it's the entire foundation of the pipeline. Set automated refresh triggers for any evergreen content that hasn't been re-crawled within 30 days. SerpApi and DataForSEO both support scheduled pulls, so use them.
3. Ignoring citation engineering Most teams treat citations as an afterthought. They're not, they're the output. Surfer's research shows that content with complete factual coverage is up to 25% more likely to be cited in AI answers. Your briefs need to explicitly flag structured facts, statistics, and authoritative sources for writers to include. Honestly, citation engineering is overtaking pure ranking tactics as the primary visibility driver in AI search, and most teams are still acting like it's 2022.
4. Producing Briefs Without LLM-Friendly Structure Clear H2/H3 hierarchies, explicit heading-level word counts, and defined semantic sections aren't just good UX, they're a competitive moat. Content with clear hierarchy consistently outperformed flat prose across AI systems throughout 2025. Build the structure into your brief template, not into the writer's instincts.
5. Measuring the Wrong KPIs Look, if you're tracking organic traffic and nothing else, you'll conclude the pipeline failed before it's had time to work. AI citations are a leading indicator, as covered in Section 8. Track them first. Everything else follows.
6. Copy-Pasting Between Tabs Instead of Integrating This is the cardinal sin the entire article argues against. Manual copy-paste between your SERP tool, your AI model, and your CMS is not a workflow, it's a bottleneck wearing a workflow's clothes. If you're still doing this after reading this far, go back to Section 5 and wire up the CMS integration. That's what the pipeline is for. Full stop.
Stop Shopping for Tools. Start Building a System.
Here's the thing: an AI content brief generator pipeline isn't something you buy off a shelf. It's something you build from three connected layers. Live SERP and AI Overview data feeds the pipeline. A vector database and RAG layer gives it memory and analytical depth. An orchestration layer , n8n, Zapier, your CMS , turns analysis into a published brief without human bottlenecks slowing everything down.
Governance keeps it honest. Measurement keeps it improving.
Teams still treating this as a tool-selection problem will keep losing ground to competitors running a fully automated SEO workflow. In a SERP where citations matter as much as rankings, speed and structural precision are the only advantages that actually hold up over time. One-off prompts from your competitors don't compound. A data-driven content strategy built on this architecture does.
Pick one of the two implementation stacks from Section 7. Audit your current briefing process today, identify the single most manual step, and automate it first.