March 19th, 2026
Content Creation Software for GEO & RAG: Tactics to Get Your SaaS Cited by LLMs
 WD
WDWarren Day
Someone asks ChatGPT, "What's the best content creation software for a small marketing team?" Your tool doesn't come up. This happens thousands of times a day, and each miss is traffic you'll never see.
AI Overviews show up in over 25% of Google searches now. Users who click through from AI-generated answers convert at 4-5× the rate of regular organic traffic. But here's what most companies miss: when someone asks Perplexity or ChatGPT for recommendations, these systems use Retrieval-Augmented Generation (RAG) to pull answers from specific sources they trust. Structure your content wrong, and you simply don't exist in that answer. Doesn't matter how good your product is.
Traditional SEO was about ranking on a results page. You wanted position one, maybe the featured snippet. Generative Engine Optimization (GEO) is different. You're optimizing to be selected as the source inside the answer itself. For companies building content creation software, this isn't some experimental channel anymore. It's becoming the main way buyers discover tools.
The gap between companies getting AI citations and those getting ignored comes down to engineering. You need content structured for machine chunking, provenance signals that LLMs actually recognize, and product APIs that feed directly into customer RAG pipelines. Schema markup helps, but it's table stakes now.
This guide walks through five specific tactics for SaaS companies in the content creation, marketing, and SEO software space. How to structure content so RAG systems can extract and cite it cleanly. Which schema types actually increase AI citations (and which ones waste your time). How to turn your product into a primary RAG source. Which authority signals LLMs are trained to trust. And how to track AI citation performance like you'd track any other acquisition channel. Your competitors will figure this out eventually. Better to be six months ahead.
The New Selection Criteria: How RAG & GEO Determine Your SaaS's AI Visibility

Here's what actually happens when someone asks ChatGPT or Perplexity for content creation software recommendations: the model doesn't "know" your product exists. It retrieves.
RAG (Retrieval-Augmented Generation) is the technical process behind most AI answers. The LLM converts the user's query into a numerical vector, searches a database of embedded content chunks for semantic matches, pulls the top 10-30 results, and synthesizes them into a response. Your SaaS either exists in that retrieval set or it doesn't.
This is fundamentally different from traditional search. Google ranks pages. LLMs cite sources. The question isn't "Where do I rank for 'content creation software'?" but "Am I in the retrieval set when an AI system searches for solutions in my category?"
Four signals determine source-worthiness in RAG systems:
Trust. LLMs prioritize content with clear authorship, publication dates, and domain authority. Pages demonstrating real experience (case studies, named customers, specific metrics) signal credibility. This is E-E-A-T adapted for machines.
Structure. RAG systems chunk your content into 300-500 token segments. Dense paragraphs get split mid-thought. Clear headings, semantic HTML tables, and FAQ blocks create clean, quotable chunks that preserve meaning. Pages with FAQ schema are 3.2 times more likely to appear in Google AI Overviews compared to pages without it.
Clarity. LLMs favor direct, self-contained answers. The first 30% of your page text generates 44.2% of all citations. If your product explanation starts after three paragraphs of preamble, you're invisible.
Freshness. Content updated within the past three months is roughly twice as likely to be cited as older content. Stale pages signal unreliable information.
The embedding layer matters more than most teams realize. Your content gets converted into a vector (a list of 384 to 1,536 numbers representing semantic meaning). Poorly structured content produces noisy embeddings that don't match user queries well. Clean structure, explicit topic statements, and schema markup improve embedding quality and retrieval precision. Not by a little. By a lot.
Properly formatted comparison tables achieve a 47% higher AI citation rate. Semantic HTML tables generate 2.5x more citations than paragraph-form content.
Look, the selection criteria have changed. Your content needs to be machine-readable, not just human-readable. That means rethinking how you write product pages, comparison content, and documentation. The companies figuring this out now are the ones showing up in ChatGPT answers while their competitors wonder why traffic's dropping.
Tactic 1: Architect Your Content for the RAG Chunker (Not Just the Human Reader)
Your content gets read twice. Once by humans, once by machines that slice it into 300-500 token chunks. Most SaaS companies optimize for the first reader and wonder why they're invisible to the second.
RAG systems don't read top-to-bottom like someone browsing your blog. They tokenize, chunk, embed, and retrieve fragments based on semantic similarity to a query. If your answer to "What's the best content creation software for remote teams?" is buried in paragraph seven after 600 words of throat-clearing, the chunker misses it completely.
Lead with the answer, always. 44.2% of all LLM citations come from the first 30% of a page's text. For product pages, comparison guides, and category content, this means the first 50-70 words must contain a direct, quotable answer. Think BLUF (Bottom Line Up Front) or a TL;DR block at the top of every high-value page. Not a nice-to-have. A requirement.
Here's the pattern: answer first, then explain the nuance.
"For teams under 20 people, [Your SaaS] delivers the fastest time-to-publish with native collaboration features and a 4.8/5 ease-of-use score. Here's why that matters..." The chunker can now extract a complete, citable statement even if it only retrieves the first 100 tokens.
Structure content as modular question blocks. Your H2 and H3 headings should read like questions your customer would actually ask: "What content creation software integrates with Slack?" or "How much does enterprise content creation software cost?" Each section under that heading becomes a self-contained 300-500 word block that answers one question completely. When a RAG system chunks your page, each block can stand alone without losing context.
Recursive text splitters preserve sentence boundaries and use heading hierarchy as natural split points. If your content is a 3,000-word narrative without clear sectional breaks, the chunker produces semantically incoherent fragments that LLMs ignore. Simple as that.
Semantic HTML is your citation multiplier. Comparison tables, feature lists, and definition content should never live in paragraph form. Use <table> for side-by-side comparisons of features or pricing. Use <dl> (definition lists) for glossary-style content. Use <figure> with <figcaption> for charts and data visualizations.
The performance gap is measurable: semantic HTML tables generate a 2.5x higher citation rate versus the same information written as paragraphs. RAG systems parse structured HTML more reliably than prose, and LLMs can extract tabular data as discrete facts without interpretation errors.
Craft 40-120 word answer snippets. Every key question on your site should have a short, self-contained answer block. Not just a heading followed by rambling paragraphs. These snippets are your citation inventory. They're short enough to fit in a single chunk, definitive enough to quote verbatim, and specific enough to be useful.
Example: "content creation software automates video editing, graphic design, and copy generation for marketing teams. The best tools for 2026 include collaborative workflows, AI-assisted editing, and multi-platform publishing. Pricing ranges from $29/user/month (starter) to $199/user/month (enterprise)."
That's 47 words. It answers three sub-questions. It's immediately citable.
Tactic 2: Deploy High-Impact Structured Data That AI Systems Actually Use
Structured data is your machine-readable handshake with AI systems. Get it right and you're looking at citation increases in the 200-300% range based on documented implementations. Get it wrong and you're either invisible or actively damaging trust.
The Five Schema Types That Move the Needle
Start with FAQPage schema for any Q&A content. This is the highest-leverage implementation for content creation software companies because it maps perfectly to how users query AI systems. When someone asks "How do I bulk schedule social posts?" your FAQ block becomes the extractable answer unit.
HowTo schema belongs on tutorial and workflow pages. If you're explaining a process like "How to create a content calendar in [Your Tool]", wrap it in HowTo markup with explicit step properties. RAG systems parse these steps as discrete, citable units.
Article or BlogPosting schema should wrap every long-form piece. Include author (with Person schema), datePublished, dateModified, and publisher properties. AI systems use these timestamps as freshness signals and author credentials as authority markers.
Product schema goes on feature pages and pricing pages. Include aggregateRating if you have reviews, offers for pricing tiers, and brand properties. This helps LLMs understand your commercial entity when answering "What does [Tool] cost?" queries.
Organization schema should live site-wide in your header or footer. Define your company with sameAs links to LinkedIn, Crunchbase, and Wikipedia if applicable. This entity disambiguation prevents AI confusion when multiple companies share similar names.
A Working Example You Can Ship Today
Here's production-ready FAQ schema for a content creation software feature page:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Can I schedule content across multiple platforms simultaneously?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes. Our [content creation software](/blog/content-creation-software-rag-seo-knowledge-sources) publishes to LinkedIn, Twitter, Facebook, and Instagram from a single dashboard. Schedule up to 100 posts per month on the Professional plan."
}
}]
}
Two Critical Warnings
Never publish schema that contradicts your visible content. If your JSON-LD says "4.8-star rating" but your page shows 4.2 stars, AI systems trained on consistency checks will flag this as low-quality. Mismatched schema is worse than no schema.
Second warning: many RAG pipelines tokenize your entire HTML (including JSON-LD) as flat text but don't semantically parse the schema structure. They see the words inside your schema, but not the relationships. This means your FAQ answers must also appear in readable HTML on the page, not only in JSON-LD. Schema amplifies discoverability for systems that parse it (Google, Bing) while the visible HTML ensures retrieval by systems that don't.
Tactic 3: Engineer Your SaaS Product as a Primary RAG Source
Most SaaS companies think of AI as a feature to add. Flip that. Engineer your product to become a preferred data source that AI systems retrieve and cite.
This isn't about slapping ChatGPT into your UI. It's about architecting your content creation software so that when a prospect asks an LLM "How do I optimize video thumbnails for YouTube?" or "What's the best workflow for batch content approval?" your product documentation, API responses, and published research are the sources the RAG system pulls from.
Build a citation-preserving API from day one. If your SaaS offers any form of content (help docs, templates, blog posts, best-practice guides), expose that content via a public or semi-public API that returns not just the text, but mandatory provenance metadata alongside it.
Every API response should include: source_url, exact_quote, publish_date, author, section_id, and content_hash. This allows downstream RAG consumers (including your own customers building AI features) to present verifiable citations instead of hallucinated answers. When a developer integrates your API into their RAG pipeline, they inherit citation integrity by default.
Example: Instead of returning {"content": "Use 1280x720 for optimal thumbnail clarity"}, return {"content": "Use 1280x720 for optimal thumbnail clarity", "source_url": "https://yourapp.com/docs/thumbnails", "section_id": "resolution-guidelines", "publish_date": "2026-01-15", "author": "Jane Doe"}.
Enable RAG-ready content exports. Your users are creating content inside your platform (blog drafts, social posts, video scripts). Let them export that content in formats optimized for vector database ingestion: JSON Lines with pre-computed metadata fields that map directly to the vector metadata schema used by Pinecone, Weaviate, Qdrant, and Chroma.
Include fields like doc_id, title, section_heading, content_chunk (pre-split at 300–500 tokens with sentence boundaries preserved), timestamp, language, and content_type. When your customers build their own RAG systems or feed content into AI tools, your platform becomes the infrastructure layer. Your brand gets cited in every downstream answer.
Offer managed embedding pipelines as a product feature. Don't make users figure out how to chunk and embed their content. Provide one-click embedding generation using battle-tested models (OpenAI text-embedding-3-large, Cohere, Sentence-BERT) with latency and accuracy benchmarks published transparently.
Embedding model selection directly impacts retrieval precision. Offering this as a managed service positions you as the technical authority. Store embeddings alongside rich metadata (document title, section anchor, publish date, author) so retrieval isn't just semantically relevant, it's citation-complete.
Publish original research in crawlable, structured formats. If you run benchmarks, user surveys, or performance studies, publish the data tables in semantic HTML with clear schema markup. Not locked in a PDF. A properly formatted comparison table showing "Average render time by video resolution" with <table> tags and Dataset schema is exponentially more citable than a paragraph summary.
Original data creates a citation moat. LLMs preferentially cite primary sources because they can't find the same data elsewhere. When you're the only source for "2026 content creator workflow benchmarks," you become the default citation for that topic.
Your product isn't just software. It's a knowledge graph node that AI systems can traverse, retrieve from, and attribute.
Tactic 4: Amplify Authority Signals That AI Systems Are Trained to Recognize
RAG systems don't just retrieve content. They weight it.
A well-structured page from a brand no one has heard of will lose to a less-optimized page from a recognized authority. LLMs are trained on the same internet that made E-E-A-T matter for Google, which means authority signals compound across both traditional and AI search. The difference now: AI systems can parse structured provenance in ways human reviewers never could.
Build a Verifiable Entity Graph
Start by implementing Person schema for every author on your site. Don't just add a name. Include worksFor properties that link to your Organization schema, sameAs URLs pointing to LinkedIn or Twitter profiles, and job titles that establish domain expertise.
Here's why this matters: When an LLM encounters your article about "best practices for video editing workflows," it can verify that the author is a named product manager at your content creation software company, not an anonymous byline. That verification path increases citation probability.
Add Organization schema to your homepage and key product pages with persistent identifiers: your company's LinkedIn URL, Crunchbase profile, and any industry association memberships. This isn't SEO theater. It's building the knowledge graph edges that AI systems traverse to assess credibility.
Pursue Third-Party Citations as Verification Nodes
The most underrated GEO tactic: getting cited by neutral, high-authority domains.
A mention in a university research paper, a TechCrunch product roundup, or an industry association report functions as a trust signal that AI systems prioritize. LLMs treat these citations as "verification nodes" (independent confirmation that your tool exists, matters, and solves real problems). One mention in a credible third-party source can carry more weight than a dozen optimized pages on your own domain.
Tactical execution: Identify the top 10 domains that LLMs cite most often in your category. Contribute data to their comparison articles. Offer your product for their "best of" roundups. Publish original research and pitch it to journalists who cover your space.
Surface Experience Evidence Visibly
AI systems increasingly reward first-hand experience (the kind of content that's hard to fabricate). For case studies, include customer logos, specific metric improvements, and dated screenshots. For product comparisons, show your actual testing methodology with timestamped evidence.
The pattern LLMs recognize: "We tested 12 content creation tools over 6 weeks using a standardized video editing workflow" signals experience. "Many users find these tools helpful" signals nothing.
Include visible bylines with headshots, publish dates, and "last reviewed" timestamps on every high-value page. These aren't cosmetic. They're machine-readable freshness and accountability signals.
Enforce a Quarterly Freshness Protocol
Content updated within the past three months is cited at roughly twice the rate of older content. Set calendar reminders to review your top 10 most important pages every 90 days.
Even minor updates matter: refresh a statistic, add a new screenshot, append a "2026 Update" section. Then update the dateModified property in your Article schema and the visible "Last updated" timestamp. Fresh content isn't just preferred, it's often required. Many RAG systems filter out stale results entirely before the ranking phase even begins.
Tactic 5: Measure AI Citation Performance Like a Core Business Metric
You can't optimize what you don't measure. Most SaaS teams obsess over organic rankings but have no idea whether ChatGPT or Perplexity recommends them when buyers ask for content creation software.
That needs to change.
The Three Metrics That Matter
Citation Frequency is your baseline. Simple math: the percentage of target prompts where your brand appears in the AI's response. Test 50 high-intent queries like "best content creation software for small teams" and you're cited in 12? Your Citation Frequency is 24%.
Share of Voice measures competitive positioning: your citations divided by total citations across all brands in the category, expressed as a percentage. If AI systems cite five competitors in response to your target queries and you appear 30% of the time, you own 30% SOV. This metric correlates directly to market perception.
Provenance Rate tracks verifiable attribution. What percentage of AI responses include your actual URL, not just your brand name? A mention without a link is awareness. A citation with a source URL is traffic. AI citation traffic converts at roughly 4.4× higher value than traditional organic, so this metric has direct revenue implications.
How to Track Without Enterprise Budgets
Start manual. Query ChatGPT, Perplexity, and Google AI Overviews weekly with your top 20 commercial-intent prompts. Log whether you appear, in what context, and with what competitors.
Tedious? Yes. But you'll spot patterns within four weeks.
For scaled tracking, tools like Semrush AI Search Visibility Checker and Answer Socrates LLM Brand Tracker automate prompt testing across models and track your SOV over time. These platforms also surface which queries you're winning versus losing, giving you a prioritized optimization roadmap.
Run Controlled Citation Experiments
Create two versions of a high-value page. One with FAQ schema and a TL;DR block, one without. Use separate, crawlable URLs (not A/B testing scripts that serve dynamic content). Let both pages get indexed for four to six weeks, then measure citation frequency for each.
This isn't theoretical. One B2B SaaS company tested a comparison table format versus paragraph prose and saw a 47% citation lift for the structured version. You're not guessing anymore. You're engineering based on data.
Look, if a 10% increase in Citation SOV translates to 15 more qualified demos per month, and your close rate is 20%, that's three new customers. Calculate your LTV and suddenly GEO has a board-level business case.
Critical Implementation Pitfalls: What Neutralizes Your GEO Efforts
You've implemented FAQ schema. You've restructured your content. You're tracking citations. But if you've made any of these four mistakes, you're invisible anyway.
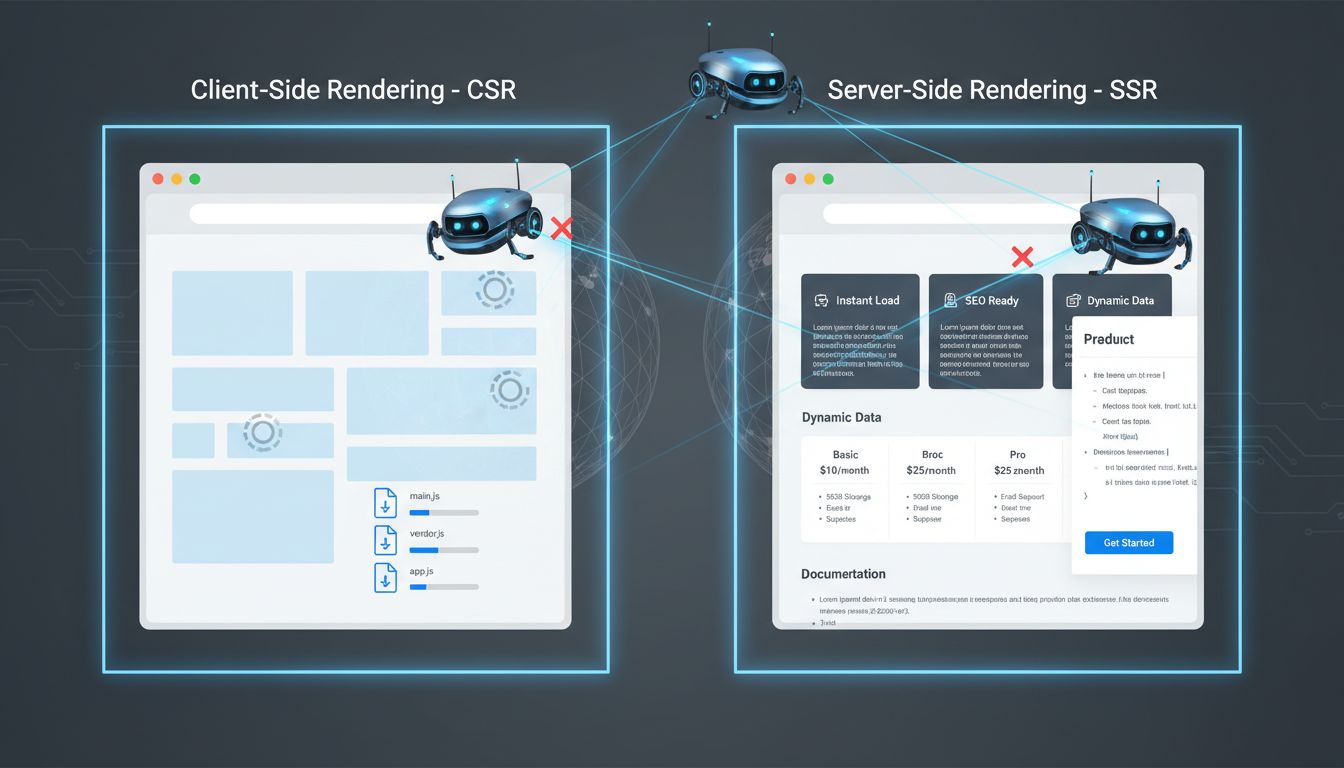
Client-side rendering is a citation killer. If your product pages, pricing comparisons, or feature documentation load via JavaScript after the initial page render, AI crawlers see an empty shell. They don't wait for React or Vue to hydrate the DOM. GPTBot, ClaudeBot, and Perplexity's crawler read the raw HTML your server returns and nothing else.
The fix: Server-Side Rendering (SSR) or pre-rendering for all informational pages. Use Next.js, Nuxt, or a static site generator for your marketing site and docs. If you must use CSR, implement dynamic rendering that detects bot user agents and serves fully-rendered HTML. Test by viewing your page source (View → Page Source in Chrome). If your core content isn't visible in that raw HTML, it's not getting indexed.
Robots.txt and meta tag misconfigurations block you silently. The most common self-inflicted wound: noindex or nosnippet meta tags on blog posts, comparison pages, or documentation. You added them during staging and forgot to remove them. Or your CMS defaulted to noindex for certain post types.
Audit every high-value informational page for <meta name="robots" content="noindex"> or X-Robots-Tag: noindex headers. Check your robots.txt file. Make sure you're not disallowing /blog/ or /resources/. Explicitly allow GPTBot, ClaudeBot, Google-Extended, CCBot, and PerplexityBot.
Slow pages don't get crawled deeply. AI bots operate on tight time budgets. If your Time to First Byte exceeds 1.2 seconds or your Largest Contentful Paint is over 3 seconds, crawlers abandon the page or index only the above-the-fold content.
Your perfectly structured FAQ at the bottom? Never seen.
Use a CDN. Optimize images. Lazy-load non-critical assets. Prioritize server response time for bot traffic. The speed fixes you've been putting off for six months? They matter now in ways they didn't before.
Hidden provenance signals waste your authority. If your publish date is only in the footer, or your author byline links nowhere, or your "Last Updated" timestamp is buried in page metadata but not visible on the page, you're not giving RAG systems the trust signals they need. Provenance must be human-readable and machine-readable at the same time. That means visible in the content body, marked up with schema, and linked to author entity pages.
Fix these four issues before you write another word of content.
Your 2026 GEO Implementation Roadmap: A Prioritized Checklist
You don't need to do everything at once. The teams getting cited fastest? They're focused on sequenced improvements, not ripping out their entire stack in a panic.
Here's your phased roadmap, organized by impact and effort.
Phase 1: This Month (Quick Wins)
Start with the three changes that need zero engineering but fix immediate signal problems.
Audit and allow key AI crawlers. Open your robots.txt right now. Verify that GPTBot, GoogleOther, CCBot, ClaudeBot, and PerplexityBot are explicitly allowed. Lots of teams blocked them early on when AI crawling first became a thing. If you're one of them, you're invisible by default. This takes ten minutes and removes the single biggest barrier to getting cited.
Add TL;DR blocks to your top three pages. Find your highest-traffic informational pages. Usually comparison guides, category explainers, or how-to content for content creation software workflows. Add a 40-70 word summary at the top of each one, structured as a standalone answer. Research shows 44.2% of citations pull from the first 30% of page text, so front-loading your answer dramatically improves your retrieval odds.
Implement FAQPage schema on one key page. Pick your most strategic comparison or category guide. Add JSON-LD FAQPage markup with 5-8 questions. Single afternoon of work. Creates an immediate structured data footprint that RAG systems can actually parse.
Phase 2: This Quarter (Strategic Foundation)
Quick wins are live. Now invest in the structural changes that compound.
Design a citation-preserving API endpoint. Build an API route that returns knowledge base articles or product docs with full provenance metadata: source URL, section heading, publish date, author, exact quote boundaries. This makes your content natively RAG-ready and positions your SaaS as infrastructure, not just another content source.
Publish original research with data tables. Commission or conduct one proprietary study. User benchmarks, industry survey data, performance comparisons, whatever fits your domain. Publish it in semantic HTML tables with clear column headers. Original datasets are structurally more citable than synthesized content and create a defensible moat.
Deploy Person and Organization schema sitewide. Add JSON-LD Organization markup to your homepage and Person schema to author pages and team bios. Include worksFor relationships, social profiles, persistent identifiers. This strengthens entity disambiguation and builds the authority graph that LLMs use to weight sources.
Phase 3: Ongoing (Optimization)
Establish the measurement and iteration rhythm that separates one-time efforts from sustained visibility gains.
Track Citation Share of Voice monthly. Set up a dashboard using tools like Semrush AI Search Visibility Checker or a custom prompt-testing script. Measure what percentage of target queries mention your brand versus competitors. Treat this metric like you treat organic ranking position, because frankly it's going to matter more in 18 months than your current position 3 ranking.
Run quarterly content freshness audits. Review your top 20 pages every 90 days. Update timestamps, refresh screenshots, add recent data points, revise at least 10-15% of the text. Recency is a primary retrieval signal, and decay happens faster in AI systems than in traditional search. The post you published six months ago? Already stale in RAG terms.
A/B test one GEO tactic per quarter. Isolate variables. FAQ schema versus no schema, table format versus paragraph, TL;DR versus no TL;DR. Measure citation frequency over a 4-6 week window. Build your own playbook based on what moves the needle for your specific category and audience, not what some consultant insists works universally.
This roadmap isn't theoretical. It's the sequence that gets you from invisible to cited within 90 days.
Conclusion
AI traffic converts at 5× the rate of traditional organic search, yet most content creation software companies remain invisible in LLM responses [Source: superlines.io]. That's your opening.
The five tactics here aren't just better SEO. They're a different game entirely. You're not optimizing for human readers anymore. You're engineering for source-worthiness. When you build content that RAG systems can actually chunk, parse, and cite with confidence, you stop competing for position 3 and start becoming the default answer.
Your product is the real moat. If your content creation software ships with managed embedding pipelines, citation-aware retrieval APIs, and provenance metadata baked into every export, you're not just optimized for AI traffic. You're infrastructure. Competitors can't replicate that with blog posts alone, no matter how well-structured.
Start small. Pick one high-intent page. Your category overview or feature comparison, probably. Break it into TL;DR blocks and semantic tables. Add FAQPage and HowTo schema. Track your citation share weekly in Semrush AI Search Visibility Checker or Answer Socrates.
The goal for 2026 isn't visibility. It's being the source AI systems trust, cite, and recommend by default.
Frequently Asked Questions
Which software is best for content creation?
Depends on what you're making and how fast you need to move. Most B2B SaaS teams don't use one tool. They use a stack.
AI Writing & Ideation: Free AI tools for content creation like ChatGPT, Jasper, or Copy.ai handle first drafts and outlines. Video & Visual Production: Descript or Camtasia for video editing, Canva or Figma for graphics. SEO & Strategy: Clearscope, MarketMuse, or Ahrefs if you care about actually ranking. Collaboration & Workflow: Notion, Asana, or ClickUp to keep projects from falling apart. Efficiency & Distribution: Buffer, Hootsuite, or free social media management tools to schedule posts and track what's working.
The best content creation software stacks have one thing in common: they export structured data and support API-driven workflows. That makes your content machine-readable for both humans and AI retrieval systems [Source: onely.com]. Without that, you're just creating content that dies in a Google Doc.
What do OnlyFans creators use to edit videos?
Professional creators split between speed and quality.
For cinematic output: Adobe Premiere Pro or Final Cut Pro give you multi-track editing, precise color grading, and full audio control. DaVinci Resolve (free version) handles color correction at a professional level. For fast turnarounds: CapCut desktop version has templates and effects built for social-first content. InShot or VN Video Editor work well for mobile-first editing when you're moving quick.
Most creators don't pick one. They use Premiere or DaVinci for hero content, then CapCut or InShot for daily posts. Canva usually comes in for thumbnails and promo graphics. It's about matching the tool to the content type, not finding the perfect all-in-one solution.
What is the basic tool for content creation?
Three tiers. Start here.
Core essentials: A writing environment (Google Docs, Notion, or Word), a visual editor (Canva for beginners, Figma if you want more control), and a video tool (Loom for screen recordings, CapCut for social clips). That's baseline. Efficiency & Distribution: free social media management tools like Buffer Free, Later, or Meta Business Suite to schedule and analyze posts across platforms. Strategic layer: Google Analytics, Google Search Console, or Ubersuggest to measure what's actually working.
Start with free versions of everything. Upgrade when you hit a real bottleneck, not because a tool looks shiny. Here's the mistake most teams make: they over-invest in ideation tools and under-invest in distribution and measurement infrastructure. You don't need another brainstorming app. You need to know what content is driving results.
How can I start content creation as a beginner?
Four steps. Don't overcomplicate this.
Step 1: Pick one platform where your audience already hangs out. LinkedIn for B2B, YouTube for education, Instagram for visual brands. Post twice per week for 90 days. Consistency beats perfection. Step 2: Use a simple framework for every piece: answer one specific question your audience asks. Structure it as problem, solution, example, call-to-action. That's it.
Step 3: Build your minimum viable toolkit. Free writing tool (Google Docs or Notion), free design tool (Canva), free scheduler (Buffer or Later). Step 4: Check native platform analytics after 30 days. Double down on the format and topic that drove the most engagement or replies.
Don't chase vanity metrics like impressions. Look for conversation and conversion signals that show real audience interest. Those tell you what's actually landing.