March 14th, 2026
Content Creation Software for RAG SEO: Building AI-Cited Knowledge Sources
 WD
WDWarren Day
Your blog post ranks #1. Traffic's flatlining anyway.
An AI Overview sits above you, answering the question before anyone clicks. ChatGPT cites your competitor when users ask about your topic. Your content is solid, keyword-optimized, backed by original research. But it's invisible to the systems now controlling 40% of search traffic.
The problem isn't your writing. It's that your content exists as a passive webpage, not an active knowledge source for AI.
Traditional content creation software like Google Docs, Canva, and video editors was built for human readers and search crawlers. AI systems like ChatGPT, Perplexity, and Google's AI Overviews work differently. They retrieve information through Retrieval-Augmented Generation (RAG). Think of RAG as a research assistant scanning millions of documents, extracting relevant chunks, and synthesizing answers with citations. If your content isn't structured for this retrieval process, you're not part of the conversation.
The #1 organic position has seen click-through rates drop 65.3% since AI Overviews launched. Self-contained chunks of 50-150 words get cited 2.3× more often than traditional long-form content. The gap between "well-written" and "AI-retrievable" keeps growing.
You need a new approach: selecting and using content creation software as part of a deliberate RAG pipeline. A connected system from ideation to distribution that transforms your content into cite-worthy knowledge assets.
This guide delivers that system. You'll learn a 5-stage RAG-optimized content workflow, the specific software stack that supports each stage, and a 7-day implementation plan designed for solo founders and small teams. No engineering degree required. Just a willingness to rebuild your content infrastructure before your competitors do.
The SEO Shift: Why RAG is Your New Content Foundation
Traditional SEO isn't dead. Keywords matter. Backlinks count. Domain authority still exists.
But the payoff has changed completely. Ranking #1 used to mean traffic. Now it means a 33.07% chance of being cited in an AI Overview, while your actual clicks drop 65.3% compared to pre-AI search. You're not competing for eyeballs anymore. You're competing to become source material.
Here's what most people miss: ChatGPT, Perplexity, and Google's AI Overviews don't read your meta description. They don't care about your keyword density. They care whether your content can be chunked, embedded, and retrieved by their RAG systems.
RAG (Retrieval-Augmented Generation) is the engine behind every AI answer you see. When someone asks ChatGPT a question, it doesn't just pull from its training data. It searches a vector database of web content, retrieves the most semantically relevant chunks, and synthesizes an answer with citations. If your content is structured right, you get cited. If not, you're invisible.
The data reveals something weird: 94% of AI citations come from pages ranking in the top 20 organic results, yet 80% also come from pages outside Google's top 100. That's not a contradiction. It's proof that AI systems use hybrid signals. Traditional SEO gets you into the retrieval pool. RAG optimization determines whether you actually get pulled from it.
Your content creation software sits at the center of this shift. Every CMS, every writing tool, every video editor you use either helps or blocks your content's retrievability. A blog post written in Google Docs and pasted into WordPress without structured headings, semantic chunking, or metadata? Functionally invisible to AI, no matter how well it ranks.
The new goal isn't traffic. It's citation frequency. How often your domain appears as a trusted source in AI-generated answers. Companies optimizing for this are seeing 2,012% increases in referral traffic from LLMs and 30,800% increases in AI Overview appearances.
This isn't future-proofing. You're already behind.
The 5-Stage RAG-Optimized Content Pipeline
Most founders treat content creation software like a junk drawer. Grab whatever's handy, use it, move on. That's why your content sits unread while competitors get cited by ChatGPT.
The difference isn't better tools. It's a connected system.
A RAG-optimized content pipeline transforms how you create, structure, and distribute content. Think of it as an assembly line where each stage prepares your work to be retrieved, understood, and cited by AI systems. Miss one stage, and your content becomes invisible to the algorithms now controlling traffic.
Here's how it works:
Stage 1: Research & Ideation – Identify what AI systems need to know and what questions they're answering. Your content creation software starts here, feeding the pipeline with strategic direction.
Stage 2: Creation & Authoring – Build content that's simultaneously human-readable and machine-parseable. Structure matters more than style. Headings, lists, clear definitions. AI can't cite what it can't parse.
Stage 3: Technical Optimization – Chunk, tag, and prepare content for vector search. This is where most teams fail. They publish without making content retrievable, then wonder why ChatGPT never mentions them.
Stage 4: Distribution & Amplification – Push content into the channels where AI systems crawl and index. Not just your blog. Syndication partners, platforms, anywhere the crawlers look.
Stage 5: Measurement & Iteration – Track AI citation rates and visibility metrics, not just page views. Did you show up in Perplexity answers? How often does ChatGPT cite your domain? These numbers tell you if the pipeline actually works.
Each stage requires specific software, but more importantly, each stage must connect to the next. Break the chain, and you're back to shouting into the void.
Stage 1: Research & Ideation – Feeding the RAG System
Your old research workflow (keyword tool, spreadsheet, outline) assumes humans are reading. They're not anymore. AI is reading first, deciding what's worth citing, then maybe sending traffic your way.
The shift here is brutal but simple: stop researching topics and start discovering knowledge gaps AI can't fill yet.
What AI is already citing matters more than search volume. Fire up ChatGPT, Perplexity, or Gemini and run your core queries. Which domains appear in the citations? What format are those answers taking? If you're never mentioned, you're not in the retrieval pool. Tools like Rankscale.ai track citation frequency across AI engines, showing you exactly which competitors are winning the RAG lottery.
Here's the uncomfortable truth: adding statistics to content improved visibility by 41%, but only if those statistics are structured as discrete, retrievable facts. A 3,000-word thought leadership piece with one buried stat loses to a 150-word chunk that directly answers "What percentage of B2B buyers research independently?"
Your research database needs to think in chunks, not articles. Ditch the Google Doc outline. Use Airtable, Notion databases, or even a structured Google Sheet with columns for: Query, Current AI Answer, Citation Sources, Knowledge Gap, Chunk Idea. Each row becomes a self-contained unit of knowledge you'll create.
This isn't about creating more content. It's about creating content that functions as a knowledge source: factual, cited, structured for retrieval. If your ideation process still ends with "write a blog post about X," you're building for 2019's algorithm, not 2025's AI engine.
Stage 2: Creation & Authoring – Building Cite-Worthy Assets
The question "Which software is best for content creation?" has no universal answer. Depends on your creator archetype, your output format, and whether your tool produces assets AI systems can actually chunk, retrieve, and cite.
Here's what most people miss: fancy software means nothing if your output is structurally opaque. A $500/month video editor won't help if your content lacks transcripts. A premium writing tool is worthless when your articles are just walls of text. AI doesn't care about production value. It cares about parsability.
You're not just writing or recording anymore. You're building a structured knowledge asset that can be extracted, verified, and cited. That changes everything about how you should author content.
The Right Content Creation Software for Your Creator Archetype
| Creator Archetype | Primary Tools & Software | RAG-Optimization Tip |
|---|---|---|
| B2B SaaS Founder | Google Docs + Grammarly (writing), Canva + Loom (visuals) | Export clean markdown. Structure articles with clear H2/H3 headings every 150–300 words to enable semantic chunking. Avoid nested formatting that breaks during conversion. |
| Video-First Creator | Descript (transcription/editing), DaVinci Resolve or Canva Video (CapCut alternatives) | Generate and publish accurate transcripts with timestamps. Timestamps become metadata for retrieval. What's replacing CapCut? DaVinci Resolve for power users, Canva Video for simplicity. |
| Podcaster/Blogger | Riverside or Descript (audio), WordPress or Sanity (publishing) | Publish show notes with key takeaways as bulleted lists. Each bullet should be a self-contained fact or insight, ideal chunk material for RAG systems. |
| Adult Content Creator (OnlyFans) | Adobe Premiere Rush or Lightworks (video), OnlyFans native tools | Focus on external, text-based content about the business of content creation. Blogs or Twitter threads on monetization strategies attract RAG traffic for meta-topics. What do OnlyFans creators use to edit videos? Premiere Rush for mobile-first editing, Lightworks for desktop workflows. |
| The Beginner | Canva (all-in-one), Apple Clips or Canva Video (easy video) | Start with a structured blog on a niche topic. Consistency in format, intro, body with subheadings, conclusion, aids future RAG integration. What tools do you need to be a content creator? A writing tool (Google Docs), a visual tool (Canva), and a publishing platform (Medium, WordPress). What's the best platform for beginners? Start with Medium or LinkedIn for built-in distribution, then migrate to owned platforms. |
Why This Matters for RAG
Every piece of content creation software you choose should answer one question: Can this output be broken into verified, citable facts?
Video editors that don't export transcripts? They fail this test. Writing tools that produce unstructured HTML? They fail. Audio platforms that skip show notes? They fail too.
The goal isn't to create more content. It's to create assets that function as knowledge sources.
Text content must use semantic HTML (H2, H3, lists, tables) that survives markdown conversion. Video and audio must generate searchable transcripts with timestamps as metadata. Visual content must include alt text and captions that describe what's shown, not just for accessibility but for retrieval.
Look, if your current content creation software doesn't support these outputs natively, you need a post-production step to add them. Descript does this automatically. WordPress requires plugins. OnlyFans requires external publishing.
The archetype table above isn't just a tool recommendation. It's a blueprint for building cite-worthy assets from day one. Choose tools that make structured, parsable output the default, not an afterthought.
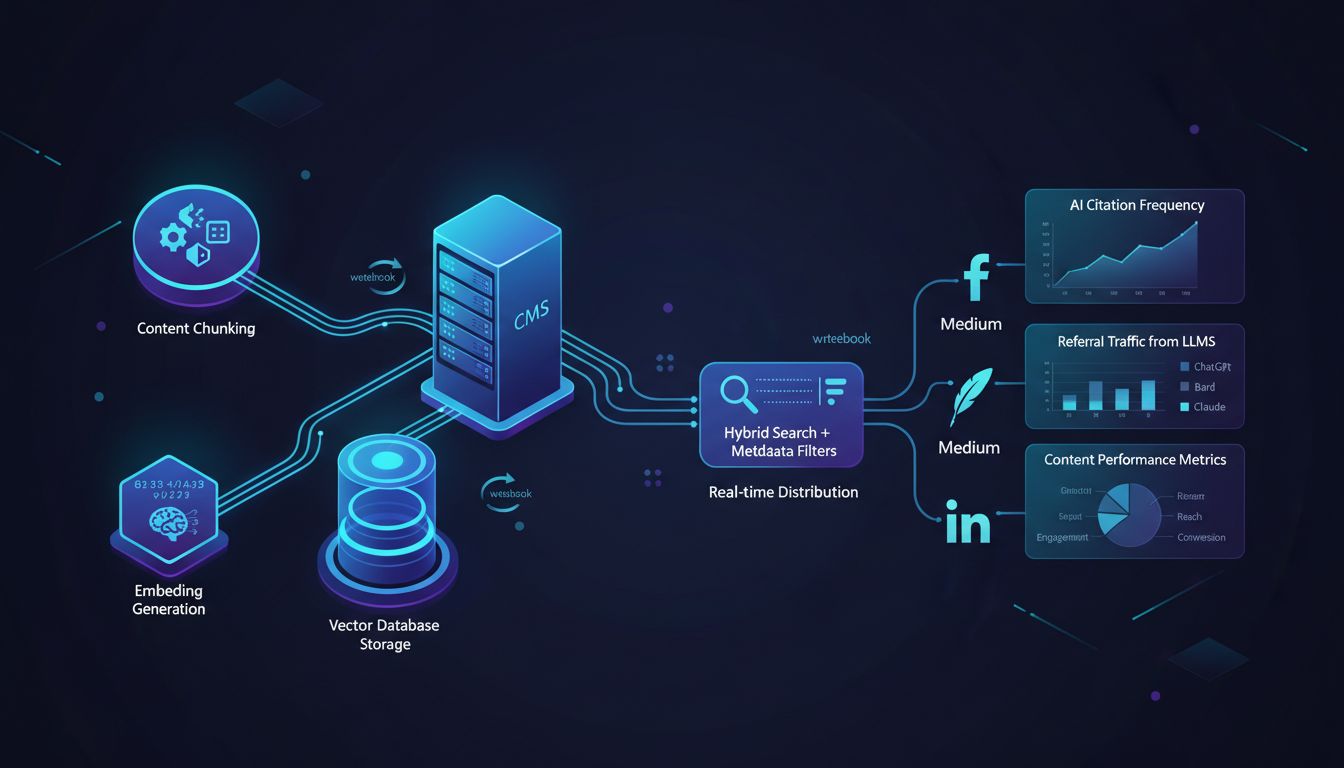
Stage 3: Technical Optimization – Preparing for AI Retrieval

You've written a brilliant 2,000-word guide. Now the hard question: can an AI system actually find the answer buried in paragraph seven?
This stage transforms your finished content from a static web page into a searchable knowledge base. Think of it as indexing your library, except the librarian is a neural network, and the card catalog is a vector database.
Your job isn't to become a machine learning engineer. You just need to understand the system well enough to manage it, audit it, or hire someone who won't gaslight you with jargon.
Chunking: The Foundation of AI Citations
Chunking breaks your content into logical segments. Paragraphs, sections, self-contained ideas.
This isn't arbitrary. Self-contained chunks of 50–150 words receive 2.3× more AI citations than sprawling, unstructured text. Retrieval systems score relevance at the chunk level, not the page level. A 3,000-word post with one relevant sentence gets ignored. A 150-word chunk that directly answers "What is embedding drift?" gets cited.
Structure-aware chunking beats fixed-size chunking every time. Instead of slicing your article every 500 characters (which might split a sentence mid-thought), smart chunking respects headings, lists, and semantic breaks. Your content creation software choice matters here. Markdown-native tools like Notion or Obsidian make structure-aware chunking trivial. WYSIWYG editors that export messy HTML? Nightmare fuel.
Common mistakes: chunks too large (diluted relevance), chunks too small (missing context), and ignoring document structure entirely (splitting tables or code blocks mid-element).
Your CMS is Now a RAG Hub
An AI-native CMS treats content as structured data, not just HTML blobs. Schemas, metadata, relationships. The difference between a filing cabinet and a database.
Implementation timelines vary wildly. A content OS like Sanity can enable a RAG-ready pipeline in 1–2 weeks. Standard headless CMS takes 6–8 weeks. Migrating a legacy WordPress monolith? Budget 3–6 months.
The killer feature: webhooks. When you hit "publish," a webhook fires, triggering automatic re-chunking, re-embedding, and upserting into your vector database. No manual exports. No stale indexes. Your knowledge base stays current without you thinking about it.
Embeddings and Vector Databases (Without the PhD)
Embeddings are numerical fingerprints for meaning.
The sentence "RAG improves citation rates" and "Retrieval-augmented generation boosts AI references" have different words but similar embeddings. They cluster together in vector space. Tools like OpenAI embeddings or Sentence Transformers generate these fingerprints. Vector databases (Pinecone, Milvus, Qdrant) store and search them at scale.
One warning: embedding drift. If you switch embedding models without re-indexing your entire corpus, retrieval quality collapses. Your old content becomes invisible because the new model speaks a different mathematical language.
Orchestration: Connecting the Pieces
Frameworks like LlamaIndex and Haystack connect your CMS, chunking logic, embedding generation, and vector database into a cohesive pipeline. They're the plumbing between stages.
For solopreneurs, all-in-one platforms like StackAI or AWS Bedrock Knowledge Bases abstract this complexity. You upload content, the platform handles chunking, embeddings, and indexing. Trade-off: less control, faster deployment.
Hybrid Search and Metadata Filtering
Pure semantic search misses exact matches.
Someone searching "Q3 2024 revenue" shouldn't get "Q4 2023 revenue" just because the embeddings are similar. Hybrid search combines keyword matching (BM25) with vector similarity. Slower, requires more storage (you're indexing twice), but retrieval accuracy improves 20–35% in most benchmarks.
Metadata is your filter layer. Tag content with author, publish date, content type, and topic. When an AI system retrieves chunks, it can filter by recency or domain expertise. A 2019 article on "best practices" shouldn't compete with your 2025 update unless the query explicitly asks for historical context.
Stage 4: Distribution & Amplification – Feeding the Ecosystem
You've built cite-worthy content. Now you need to get it where AI systems can find it.
Distribution used to mean "drive traffic." Now it means "maximize retrievability surface area." Every platform you publish to is another entry point for AI crawlers scanning for authoritative sources. More surfaces, more chances to get cited.
Start with social media, but think differently. Instead of just dropping links, extract self-contained chunks, a stat, a definition, a contrarian take, and post them as standalone content. Each post becomes a potential citation trigger when someone asks ChatGPT or Perplexity about your topic. Use free social media management tools like Buffer, Hootsuite's free plan, or Later to schedule these micro-chunks across platforms without burning your day.
But social is just the appetizer.
Syndicate full pieces to Medium, Dev.to, LinkedIn Articles, or industry newsletters, always with canonical links pointing back to your source. AI crawlers consume content 38,000 times faster than they refer traffic back, so you need presence everywhere they're indexing. Yes, that ratio sounds absurd. It's also accurate.
The technical layer matters too. Submit XML sitemaps to Google and Bing. Audit your robots.txt to make sure you're not accidentally blocking AI user-agents (unless you've made a strategic decision to). Platforms like Substack and LinkedIn are heavily indexed by AI systems, publishing there isn't just audience-building, it's RAG infrastructure.
Your content isn't static anymore. It's a living knowledge asset that needs to circulate through the ecosystem where AI models hunt for answers. Feed it everywhere the crawlers look, or watch your competitors show up in citations while you wonder why your traffic flatlined.
Stage 5: Measurement & Iteration – Tracking AI Success
Your Google Analytics dashboard is lying to you. Pageviews, bounce rate, time on page, these metrics tell you nothing about whether ChatGPT is citing your content or Perplexity is ignoring it.
You need different KPIs now. Start with AI Citation Frequency: how often your domain appears in AI-generated answers for queries in your niche. This is your north star metric. If you're not being cited, nothing else matters.
Track referral traffic from AI platforms separately. Set up UTM parameters and analytics segments to isolate traffic from "Google AI Overviews," "ChatGPT," and "Perplexity." One case study documented a 2,012% increase in referral traffic from LLMs after implementing RAG-optimized content strategies. That's not a typo.
Monitor which content types get cited most. Are your statistical listicles outperforming your how-to guides? Does ChatGPT prefer your comparison tables over your narrative case studies? This data feeds back into Stage 1, your research and ideation process.
Manual monitoring still works. Search for your brand and core topics weekly in Perplexity, Claude, and ChatGPT. Screenshot citations. Track which competitors appear alongside you. Note which sources AI systems prefer when you're not cited.
Here's the thing: the feedback loop is everything. If AI systems consistently cite your "SaaS pricing models" content but ignore your product announcements, you have a clear signal. Create more analytical, data-driven content and less promotional material. They're telling you exactly what they value.
Measurement isn't the end of your pipeline. It's the beginning of the next cycle.
Your First RAG Pipeline: A 7-Day Implementation Plan for Solo Founders
You've read the theory. Now you need to build something that works.
This plan assumes you have 5-10 published blog posts and can follow a tutorial (or copy-paste code). You don't need to be a developer. You need one focused week.
Pre-flight check: Pick your 3 best-performing posts, the ones that already rank or answer specific questions. You'll use these as your test corpus.
Day 1-2: Audit & Chunk Your Content
Open a Google Doc. For each of your 3 posts, manually extract the key sections, definitions, how-to steps, statistics, examples, into self-contained 50-150 word chunks. Each chunk should answer one question or make one point without requiring surrounding context.
Label each chunk with metadata: post title, section heading, URL, publish date.
This manual work teaches you what "cite-worthy" actually looks like. You'll automate it later, but start by understanding the pattern. Think of it like learning to chop vegetables before you buy a food processor.
Day 3-4: Choose Your Low-Cost Stack
You need three components: a way to convert your content to clean text, an embedding model, and a vector database.
Conversion: Use Firecrawl's /scrape endpoint (free tier: 500 requests/month) to turn your URLs into clean markdown.
Embeddings: OpenAI's text-embedding-3-small costs $0.02 per million tokens, your 3 posts will cost pennies.
Vector DB: Start with Pinecone's free starter pod (1 index, 100k vectors) or run Chroma locally if you prefer zero cost.
Sign up for accounts. Generate API keys. Test each tool individually before connecting them. Don't try to wire everything together on day one.
Day 5: Create Your First Index
Use LlamaIndex's quickstart pattern, it's 20 lines of Python that loads documents, chunks them, generates embeddings, and stores vectors. If code intimidates you, use StackAI's no-code connector or Haystack's visual pipeline builder.
Run the script. Watch your chunks get embedded and indexed.
This is your RAG system's memory forming. Honestly, seeing it work the first time is weirdly satisfying.
Day 6: Test Retrieval
Build a simple chat interface using the same LlamaIndex setup with GPT-4o-mini as your generator. Ask questions your content should answer: "How do I optimize meta descriptions?" or "What's the click-through rate for position 1?"
Does it retrieve your chunks? Does it cite your URLs?
If not, adjust your chunk size or add more specific metadata. Most first-time issues come from chunks that are either too granular (one sentence fragments) or too bloated (entire sections that should've been split).
Day 7: Plan Your Integration
Set up a Zapier or Make.com automation: when your RSS feed updates, trigger a webhook that adds the new post to your pipeline. You won't perfect this today, just prove the connection works.
Document what you learned. Note which chunks retrieved well and which didn't. Plan Phase 2: adding more content, metadata filtering by topic, and A/B testing different chunk sizes.
This isn't production-ready. It's a learning pipeline that proves you can build the system that will eventually feed AI engines with your content. The difference between founders who talk about RAG and founders who actually deploy it? They built the messy v1.
Critical Mistakes That Break Your RAG Pipeline and Kill AI Visibility
You can build the perfect content creation workflow and still watch your AI visibility crater. Here are six mistakes that silently destroy RAG pipelines, and how to spot them before they cost you traffic.
1. Relying on Traditional SEO Metrics Alone
Domain authority and backlink counts don't tell you whether ChatGPT will cite you. Traditional metrics fail to predict RAG retrieval because AI systems evaluate semantic relevance and chunk-level quality, not page-level authority signals. They're looking at whether your content directly answers a question in a format they can extract and cite.
Consequence: You spend months building backlinks while AI engines ignore your content entirely.
2. Bad Chunking Strategies
Chunks that are too large (over 800 tokens) or too small (under 50 words) break retrieval. Worse, using naive fixed-length chunking on complex documents destroys context boundaries, splitting tables mid-row or code blocks mid-function.
Structure-aware chunking isn't optional. It's the difference between being cited and being invisible.
Consequence: AI retrieves incomplete information or skips your content for better-structured competitors.
3. Ignoring Embedding Drift
You switch from OpenAI's ada-002 to a newer embedding model without re-indexing your vector store.
Your old embeddings and new queries now live in different mathematical spaces. They can't talk to each other. Relevant content returns zero results because you're essentially running a search engine with a corrupted index.
Consequence: Your entire retrieval system becomes misaligned overnight.
4. No Metadata Filtering
You chunk and embed content but skip metadata tags, no publication date, no content type, no source authority markers.
Consequence: AI systems can't filter for recency or credibility. Your 2022 pricing guide gets retrieved for 2025 queries. Fresh, accurate content from competitors wins the citation every time.
5. Forgetting Caching & Cost Controls
Every query triggers new embedding API calls and LLM generations. No prompt caching, no response reuse, no semantic deduplication. What worked for 100 queries a day breaks at 10,000.
Consequence: Your bill explodes as traffic scales. Response latency climbs into the seconds, then the tens of seconds.
6. Assuming Citations are Accurate
Research shows between 50% and 90% of AI-generated citations don't fully support the claims they're attached to.
You assume being cited means being cited correctly. Look, getting mentioned isn't enough if the AI is misrepresenting what you actually said or attaching your URL to claims you never made.
Consequence: You must verify that AI systems are actually representing your content accurately, not just dropping your domain name while making unsupported claims.
The Future-Proof Stack: RAG Trends Shaping 2026 and Beyond
The RAG pipeline you build today won't look the same in 18 months. But if you've built on the right foundations, you'll adapt instead of rebuild.
GraphRAG is replacing flat vector search. Traditional RAG treats your content as isolated chunks floating in vector space. GraphRAG adds a knowledge graph layer, explicit relationships between entities, concepts, and documents. The result: 35–46% improvement on multi-hop queries where AI needs to connect information across multiple sources. One engineering case study reported 80% reduction in storage overhead and 74× faster startup times. Your content doesn't just get retrieved, it gets reasoned over.
Agentic RAG will dominate by 2027. AI agents, autonomous systems that research, plan, and execute tasks, are already using RAG patterns to access knowledge. Your content won't just answer questions. It'll become fuel for digital workers booking meetings, drafting proposals, and making purchasing decisions without human intervention.
Managed lifecycles are abstracting complexity. AWS Bedrock Knowledge Bases and similar services now automate ingestion, chunking, embedding, and indexing. You upload content; the platform handles the RAG plumbing. This matters for small teams, you can compete without hiring an ML engineer.
Evaluation frameworks will become mandatory. By 2026, systematic quality measurement (RAGAS, Galileo) will be standard in enterprise deployments. You'll track groundedness, citation accuracy, and retrieval precision, not just traffic.
Your insurance policy: build on API-first, headless infrastructure. When GraphRAG becomes table stakes, you'll integrate it in days, not months.
Conclusion
Your content creation software choices aren't about features anymore. They're about whether your content gets cited when AI answers questions in your niche.
Here's what matters: every tool, every workflow needs to feed the RAG pipeline. Not because it's trendy, because AI systems are already deciding which content gets used and which gets ignored. The #1 organic position lost 65.3% of its click-through rate since AI Overviews launched [Source: ziptie.dev]. Traditional rankings still open doors, but citation is what closes deals.
You don't need to code. You need to think structurally when you pick content creation software. Choose tools that output chunked, machine-readable content. Build workflows that separate writing from technical optimization. Track how often you get cited, not just how many people visit.
The 7-day plan isn't ambitious. It's the minimum to stay visible. Pick one content type, chunk it correctly, add structured data, distribute it strategically, and measure what AI systems actually retrieve.
Your next step: Open your content calendar. Pick one high-value asset. Run it through the 5-stage pipeline this week. Track citations. Scale what works.
The RAG era rewards action over perfection.
Frequently Asked Questions
How to make $10,000 a month on OnlyFans?
You need multiple revenue streams working together: subscriptions, tips, pay-per-view content, and direct messages. Most creators hitting $10K monthly have 500-2,000 active subscribers, but the number alone doesn't tell the story.
This is a real business, not passive income. You're looking at daily content creation, community management, and marketing across multiple platforms. The content creation software you choose, editing tools, scheduling platforms, analytics, directly determines whether you can maintain this pace without burning out.
How many OnlyFans subscribers do you need to make $1000?
The typical range is $5-$10 per subscriber monthly when you combine subscriptions with tips and PPV content. So you'd need roughly 100-200 active subscribers to hit $1,000 per month.
But subscriber count is just one piece. Engagement rate, content pricing strategy, and retention matter more than raw numbers. A creator with 100 engaged subscribers often outrearns someone with 500 passive ones.
How to start content creation as a beginner?
Pick one platform and one content format you can actually sustain long-term.
Look at what you already have, knowledge, perspective, existing assets. Identify 3-5 core topics where you've got something real to say. Then implement a simplified version of the 7-Day RAG Pipeline Plan: set up basic research feeds (day 1-2), choose one authoring tool and create your first piece (day 3-4), optimize it with clear structure and self-contained sections (day 5-6), then distribute and measure (day 7).
Your goal in the first 30 days isn't perfection. It's consistency and learning what your audience actually responds to.
How many views does a YouTube video need to make $1000?
YouTube CPM (cost per thousand views) typically runs $3-$5 for most niches, so you'd need roughly 200,000-330,000 views to earn $1,000.
Revenue swings wildly by niche. Finance and B2B SaaS content can hit $15-$25 CPM, while entertainment often sits below $2. These numbers assume you're monetized and account for YouTube's 45% revenue share.
The shift to AI-driven discovery changes the game. Optimizing for both traditional YouTube search and LLM citation is now necessary for sustainable view growth, not optional.