April 2nd, 2026
How to Automate Your SEO Content Briefs with an AI Generator
 WD
WDWarren Day
Every new piece of content on your roadmap starts the same way: pull up the SERP, tear apart the top ten results, copy competitor headings into a template, layer in keyword data from Ahrefs, and somehow distil all of that into a brief a writer can actually use. Multiply that by twenty keywords a month and you've got a full-time job that isn't writing a single word.
The bottleneck isn't your writers. It's briefing.
An AI content brief generator sounds like the obvious fix. And honestly, it is -- but most teams get this wrong. They subscribe to a single tool, get frustrated by the generic outputs, and write the whole thing off. That's not an AI problem. That's an approach problem.
The real version of an AI content brief generator isn't something you set and forget. It's a system you build -- one that connects keyword research data, LLMs, and automation platforms into a repeatable pipeline, with human quality gates that stop it from producing content that ranks nowhere. There's a meaningful difference between the two, and most teams never get there because nobody explains what that system actually looks like.
I've built it. This article is the blueprint.
What follows covers the full stack: how to deconstruct what a genuinely useful brief contains, which tool combinations support different levels of technical investment, a step-by-step build guide for your seo content automation pipeline, and the QA framework that keeps quality from collapsing at scale.
Why Manual Content Briefs Are an Unsustainable Bottleneck
Here's the honest accounting of what a manual content brief actually costs: SERP analysis, competitor teardown, heading extraction, intent mapping, keyword clustering, internal link identification. Done properly, that's 2–4 hours per brief. For a team targeting 8–10 pieces a month, you've just consumed an entire working week before a single word of content is written.
That's not a workflow problem. It's a capacity ceiling.
The strategic cost compounds things. When a technical SEO is spending Tuesday afternoon copying H2s from competitor articles into a Google Doc template, they're not working on site architecture, crawl budget, or the internal linking structure that actually moves the needle. Manual briefing doesn't just slow content production -- it crowds out the higher-leverage work that no automation can replace.
84% of marketers report that AI has improved the speed of content delivery, according to Arvow's 2026 content marketing research. That's not a marginal gain.
The problem hits mid-tier domains hardest. Operating at a DR 33, you can't win on authority alone. You need volume and quality -- topical depth, consistent publishing cadence, well-structured briefs that give writers a genuine shot at ranking. Manual processes make that combination arithmetically impossible with a lean team.
The answer isn't to lower the bar on brief quality. It's to stop treating brief creation as a manual craft and start treating it as an engineering problem: repeatable inputs, predictable outputs, measurable throughput. That's exactly where an ai content brief generator earns its place in the stack -- not by replacing the expertise that makes a brief useful, but by removing the mechanical labour that stops that expertise from scaling.
Deconstructing the AI-Optimized Brief: From Generic to Actionable
A content brief has one job: eliminate guesswork for the writer. Not "here are some keywords to include," but "here is the exact argument to make, the structure to follow, the gaps the top-ranking pages missed, and the sources that will make this credible." Anything short of that is a planning document dressed up as a brief.
Most AI-generated briefs are structurally competent and strategically empty. Feed a keyword into a generic tool and you'll get H2s that mirror the top three results, a keyword list pulled from the SERP, and a word count suggestion. It's not wrong -- it's just indistinguishable from every other brief targeting that keyword. That's the beige content trap.
The components that separate a weak brief from an actionable one:
| Component | Weak AI Brief | Robust System Brief |
|---|---|---|
| Keywords | Primary keyword + 3 generic LSI terms | Clustered primary/secondary keywords mapped to intent and funnel stage |
| Structure | H2s copied from top-ranking results | H1–H3 scaffold built from gap analysis, not imitation |
| Competitive insight | "Competitors cover X, Y, Z" | Specific gaps: what top 5 results don't address |
| Angle Injection | None | Explicit contrarian or differentiating argument the writer must take |
| E-E-A-T signals | None | Required sources, data points, author credentials to reference |
| Meta title/description | Generic suggestion | Drafted to spec with character counts |
| PAA questions | Sometimes listed | Mapped to specific sections with answer format guidance |
| Internal links | None | Actual target URLs from your site's existing content |
| Word count | "1,500–2,000 words" | Data-driven range based on median competitor length |
| Brand voice | None | Explicit tone directives and phrases to avoid |
Angle Injection is the secret weapon. It's the one field that forces a real strategic decision: what is this piece actually going to say that the existing top results don't? It might be a contrarian position, a proprietary data point, or a perspective rooted in direct experience. Without it, your writer has no choice but to produce a competent summary of what already ranks -- and a competent summary of what already ranks won't outrank anything.
The ai content brief generator assembles the data. You define the angle. That division of labour is what turns an SEO content brief template into a genuine competitive weapon rather than a formatted checklist.
Architecting Your Tool Stack: From No-Code to Full-Code Pipelines
Before writing a single prompt, you need to make an architectural decision. The tool you choose shapes everything downstream -- what data you can feed the AI, how much you can customise the output, and whether the whole thing breaks when you hit volume. Three distinct paradigms exist here, and the right one depends almost entirely on your team's technical capability.
| Approach | Best For | Core Tools | Pros | Cons |
|---|---|---|---|---|
| Turnkey SEO-AI Suite | Marketers who need results this week | Frase, Surfer SEO, SEOBoost, MarketMuse | Fastest time-to-value; SERP data and AI in one interface | Expensive at scale; limited customisation; black-box data processing |
| No-Code Connector | Teams comfortable with SaaS but not code | Zapier + ChatGPT + Ahrefs/Semrush | Connects best-in-class tools; no engineering required | Per-task pricing gets painful at volume; limited conditional logic; no real-time SEO data unless you explicitly pipe it in |
| Programmable Hybrid | Engineers and technical founders | n8n or custom scripts + LLM API + SEO APIs | Maximum control; cost-efficient at high volume; self-hostable | Highest setup overhead; requires ongoing maintenance |
Option 1: Turnkey SEO-AI Suites
Tools like Frase, SEOBoost, and Surfer pull SERP data and generate structured briefs inside a single interface. For a solo marketer or a small team without engineering support, this is a perfectly reasonable starting point.
The tradeoff is real, though. You're working within whatever brief template the tool ships with. You can't inject your own brand context, proprietary data, or custom scoring logic, and you can't touch the underlying prompt. That last part matters more than most people realise.
Pricing across this category is volatile. I've seen conflicting figures across multiple sources for the same tools, so check vendor sites directly before budgeting.
Option 2: No-Code Connectors
Zapier connecting Ahrefs exports to ChatGPT and dumping outputs into Notion is a legitimate pipeline. It's accessible, it works, and you can get something running in an afternoon.
The ceiling is low, though. Zapier's per-task pricing model gets expensive quickly at scale, and the linear workflow logic makes it awkward to build anything with branching decisions or parallel processing. Make.com handles complexity better at a lower price point, which makes it the smarter no-code choice for anything beyond simple linear automations.
Option 3: The Programmable Hybrid
This is what I run at Spectre, and it's what I'd recommend to any technical founder who's serious about scale. n8n's execution-based pricing and full JavaScript support let you build genuinely complex pipelines -- pulling live SERP data via the DataForSEO API, passing structured context to Claude or GPT-4, applying custom scoring logic, and pushing finished briefs to your CMS.
There's a community-built n8n workflow that does exactly this: keyword in Google Sheets triggers a SERP pull, Claude generates the brief, a second AI pass drafts the article, and it lands in WordPress as a draft. That's the skeleton. The real value comes from what you bolt on top of it -- your own scoring logic, your brand context, your ai content brief generator layer sitting in the middle.
How to choose
Honestly, it's simpler than it looks. Marketer without engineering support? Start with a turnkey suite or Make. Technical founder or developer on the team? Skip the middle ground and go hybrid. The no-code connector layer is useful for prototyping, but it's rarely where you want to land permanently.
Building the Pipeline: A Step-by-Step Technical Blueprint
This is where the architecture from the previous section becomes executable. The pipeline has four discrete stages, and each one has a specific job. Conflating them is where most implementations fall apart.
[Keyword Cluster] → [Data Ingestion] → [Brief Generation] → [QA Gate] → [CMS Push]
Step 1: Data Ingestion
The brief is only as good as the data feeding it. I pull from three sources in sequence.
Keyword data via the Ahrefs API. I query by keyword cluster and immediately apply a competitiveness filter. For a site sitting at DR 33, I filter to keyword_difficulty < 40. Chasing KD 70+ keywords on a mid-authority domain wastes LLM tokens and writer time. Here's a simplified version of the enriched payload that gets passed downstream:
{
"keyword": "[AI content brief generator](/blog/ai-content-brief-generator-how-to-automate-seo-outlines-2026)",
"volume": 40,
"kd": 4,
"intent": "transactional",
"cluster": "[content automation](/blog/content-creation-software-for-ai-seo-automation-2026)",
"dr_filter_applied": true,
"dr_threshold": 40
}
SERP data via DataForSEO. For each keyword that passes the filter, I fetch the top 10 organic results -- titles, URLs, estimated word counts, and any SERP features like featured snippets and PAA boxes. This is the competitive landscape the LLM needs to reason about.
GSC enrichment. For keywords where you already have impressions but low CTR, I pull that signal from Google Search Console and flag it in the payload. These are re-optimisation candidates, not net-new briefs -- a distinction the pipeline should handle differently.
Step 2: Brief Generation Engine
The enriched JSON from Step 1 goes straight into the LLM prompt. The model never guesses at search volume or competitor structure -- it's grounded in live data, which is your primary defence against hallucination.
Here's the prompt structure I use (simplified):
You are an expert SEO content strategist. Using the structured data below,
generate a content brief in JSON format.
INPUT DATA:
{{keyword_payload}}
{{top_10_serp_titles_and_urls}}
{{paa_questions}}
OUTPUT FORMAT:
{
"target_keyword": "",
"search_intent": "",
"recommended_title": "",
"meta_description": "",
"suggested_h2s": [],
"secondary_keywords": [],
"paa_to_address": [],
"competitor_gaps": [],
"word_count_target": 0,
"internal_link_suggestions": [],
"angle": ""
}
Do not invent statistics. Do not add keywords not present in the input data.
That last instruction matters more than it looks. Without an explicit constraint, GPT-4 and Claude will fabricate plausible-sounding search volumes and competitor claims. The angle field is where you inject differentiation -- the one thing this piece will say that the top-ranking results don't.
This is precisely the architecture behind the n8n SERP → Claude → WordPress workflow, which chains Google Custom Search, Claude, and the WordPress REST API into a single automated pipeline. It's a clean proof of concept for this exact pattern.
Step 3: Human-in-the-Loop QA Gate
The LLM output gets written to a Notion database (or a Google Doc, depending on your team's tooling) -- not directly to the CMS. This is a hard stop, not optional.
An editor reviews the brief against a checklist before it moves forward. I'll cover that checklist in full in the next section. The key questions at this gate are: Does the angle hold up? Are the H2s differentiated from the top three results? Has the model hallucinated any data points?
Step 4: CMS Push
Once the brief is approved, a webhook triggers a draft creation via the WordPress REST API -- title, meta fields, and the brief content pre-populated in a custom field or post body. The writer opens a draft that's already structured. They're not starting from a blank page.
On error handling: every API call in the pipeline needs a failure state. Failed Ahrefs calls should log to a monitoring table and skip -- not crash the workflow. Poor-quality LLM outputs (you can score these by checking whether required JSON fields are populated) should route to a separate review queue, not silently pass through to QA.
The pipeline isn't magic. It's a series of conditional logic gates with API calls between them. Build it that way and it's maintainable. Treat it as a black box and you'll spend more time debugging it than you saved building it.
The Non-Negotiable QA Checklist: Safeguarding Quality at Scale

The pipeline does the heavy lifting. The QA gate is what stops it from burning your site down.
Automation without quality control doesn't scale content production -- it scales content risk. Every brief that skips review is a potential hallucination, a plagiarised structure, or a piece of "beige content" that quietly erodes your site's seo content quality signal at the domain level. Google's helpful content system operates site-wide. One hundred mediocre AI briefs don't just underperform individually -- they drag everything else down with them.
This is the one stage where human expertise is irreplaceable. Not optional. Irreplaceable.
The AI Content QA Checklist
Use this as your final human gate before any brief moves to a writer or into production.
Category 1: Factual & Source Accuracy
- Are all statistics attributed to a named, verifiable source -- not "studies show"?
- Have you spot-checked at least two data points against the original source URL?
- Are any dates, product names, or quoted figures cross-referenced? (LLMs hallucinate these with alarming confidence.)
- Does the brief flag which claims need primary source verification by the writer?
Category 2: E-E-A-T & Brand Voice (where the "beige content" problem lives)
- Is there a unique angle, proprietary insight, or first-person perspective baked into the brief -- not just a rehash of what the top-ranking page already covers?
- Does the brief specify tone, vocabulary, and any brand-specific terminology?
- Is there a clear signal of experience -- a case study hook, a real-world scenario, a named tool or workflow?
- Would a reader be able to tell which brand produced this, or could it have come from anyone?
If you can't answer yes to that last question, the brief fails. Full stop. This is the eeat checklist category that most teams skip, and it's exactly why their AI content sounds identical to their competitors'.
Category 3: SEO Mechanics
- Is the primary keyword placed naturally in the H1, first paragraph, and at least one H2 -- without forcing it?
- Does the heading structure logically follow the search intent (informational vs. transactional)?
- Are internal linking suggestions contextually relevant, not just topically adjacent?
- Is the recommended word count grounded in SERP analysis, not an arbitrary round number?
Category 4: Duplication & Competitor Differentiation
- Run a sample paragraph through Copyscape or a similar tool. Does it flag structural similarity?
- Is the brief's proposed outline meaningfully different from the #1 ranking page -- not just a reordered version of the same H2s?
- Does the brief include a differentiation directive: what angle, data, or format will make this piece better, not just equivalent?
Category 5: Actionability
- Can a writer execute this brief without needing to ask a single clarifying question?
- Are word count, format, target audience, and CTA all specified?
- Are the "questions to answer" concrete enough that a writer knows when they've answered them?
Any brief that fails two or more checks in a single category goes back through the pipeline with corrective prompt instructions -- not to a writer. That feedback loop is also how your prompts get better over time. Every QA failure is a data point telling you exactly where your ai content brief generator has a gap. Fix it at the source, not at the end.
Measuring Success: KPIs for Your Automated Briefing System
Counting articles published is a vanity metric. It tells you nothing about whether your pipeline is working, or whether the content it's producing is actually moving the needle.
Production Velocity & Efficiency
Start with the baseline: time per brief, before and after. In most teams I've seen, this drops from 90-120 minutes to under 20. Track briefs generated per week and, critically, writer satisfaction scores. If writers are constantly overriding brief sections or going off-script, that's a signal your prompts are producing outputs they don't trust.
Brief & Content Quality
Brief acceptance rate is the percentage of AI-generated briefs that pass QA without being sent back through the pipeline. Anything below 80% means your prompts or data inputs need work. Pair this with average Surfer or Clearscope optimization scores at the point of submission. If your auto-briefed content consistently hits target scores pre-publication, the pipeline is doing its job.
SEO Impact via Cohort Analysis
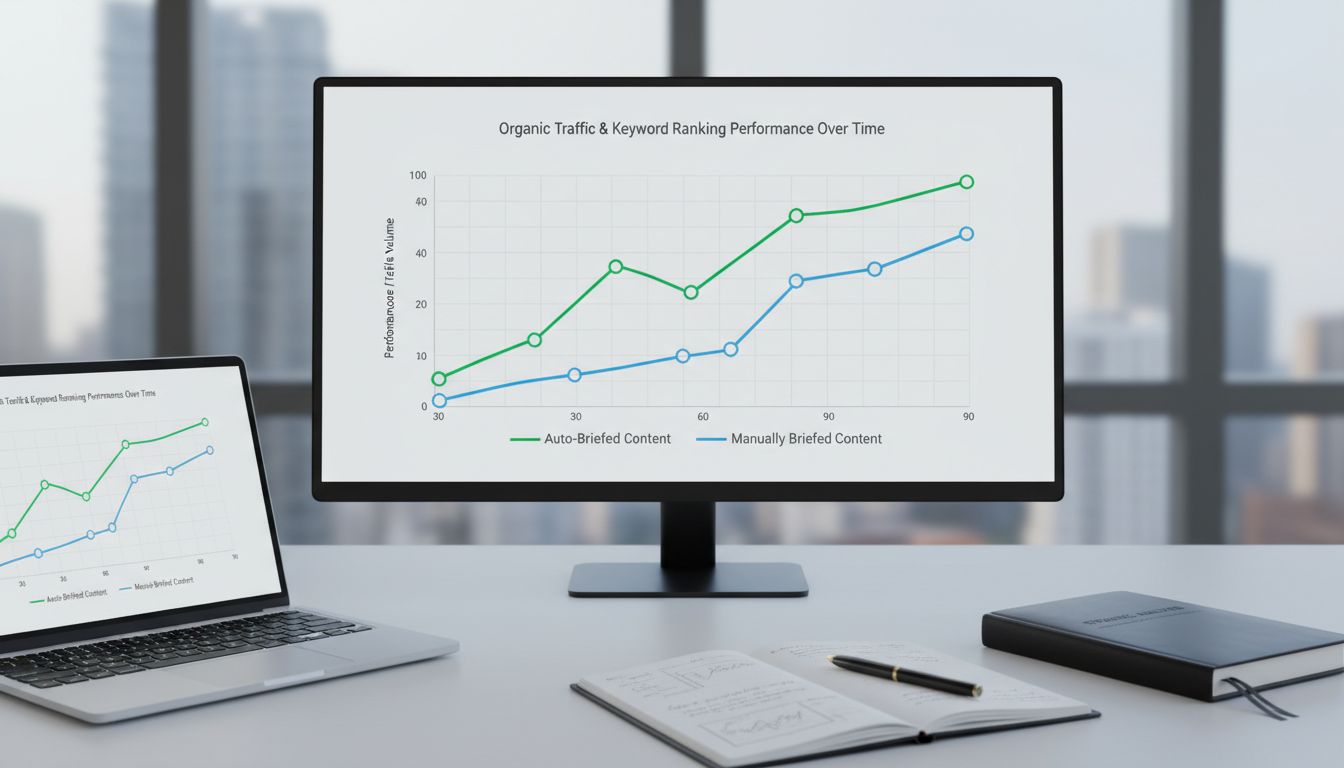
Most teams skip this one. It's also the most important.
Split your published content into two cohorts -- auto-briefed and manually briefed -- and track organic traffic and keyword rankings at 30, 60, and 90 days. Don't compare individual articles. Compare cohort averages. This controls for topic difficulty and domain fluctuations, giving you a statistically honest read on whether the system produces content that actually ranks.
The Financial Reality
The maths is straightforward: labour savings from brief production plus increased output volume, minus tooling costs. One community case study reported 602% ROI on an automated AI content project. That's not typical, but even conservative gains compound quickly once your ai content brief generator is running at volume.
Use these KPIs iteratively. A drop in brief acceptance rate tells you to fix your prompts. A cohort underperforming at 90 days tells you to revisit your SERP data inputs. The metrics aren't just scorecards -- they're your system's debugging interface.
Common Pitfalls & How to Mitigate Them
Building an automated briefing pipeline is genuinely useful. It's also genuinely capable of making your SEO situation worse if you skip the guardrails. Here are the failure modes I've seen, and how to prevent them.
Pitfall 1: The Beige Content Avalanche
This is the most insidious ai content pitfall. LLMs are trained to produce statistically likely output, which means they default to the median of everything they've seen. Scale that up and you get hundreds of briefs that all say roughly the same thing, in roughly the same structure, with roughly the same angle. None of it is wrong. None of it will rank.
The fix is mandatory angle injection at the prompt level. Every brief template should require a unique POV field: a contrarian take, a proprietary data point, or a first-person experience no competitor can replicate. If the pipeline can't populate that field automatically, it should flag the brief for human input before moving forward.
Pitfall 2: LLM Hallucination in SEO Briefs
Models invent statistics, misattribute quotes, and fabricate citations with complete confidence. The mitigation is source-grounding: instruct the model explicitly to use only the provided SERP data and input context. Build a mandatory citation field into your brief template. If a claim appears without a source, the QA gate should reject it.
Pitfall 3: Over-Optimisation and Keyword Stuffing
Tell an LLM to "optimise for SEO" and it will stuff your target keyword into every other sentence. Prompt for natural language inclusion instead, and use tools like Surfer as a post-draft scoring layer, not as a brief input that the model tries to satisfy mechanically.
Pitfall 4: The Ranking Drop
This one has hard data behind it. SE Ranking's 16-month experiment found that fully AI-generated content on new domains generated early impressions but collapsed in rankings around the three-month mark, and largely didn't recover. AI-assisted content that was properly edited continued to perform. The pipeline produces raw material. A human has to finish the job.
Pitfall 5: Data Privacy and Security
Feeding client data, internal metrics, or customer PII into a public LLM API is a liability. Use local or self-hosted models for anything sensitive, and verify that your vendor agreements cover data processing. This isn't theoretical, it's a contractual and regulatory exposure.
Pitfall 6: Tool Lock-In and Cost Creep
No-code pipelines are fast to build and easy to outgrow. Monitor usage tiers actively. Zapier and Make costs scale with execution volume in ways that aren't obvious until the invoice arrives. For custom builds, design modularly: your LLM provider, SERP data source, and automation layer should each be swappable without rebuilding the whole system.
None of these pitfalls are reasons to avoid building the pipeline. They're reasons to build it carefully.
The Bottom Line
An AI content brief generator isn't something you buy off a shelf and plug in. It's a system you build, connecting keyword data, LLM intelligence, and automation tooling into a repeatable SEO content pipeline that compounds in value over time.
The grunt work, SERP scraping, competitor analysis, heading extraction, intent mapping, is exactly what machines should be doing. Your job is to define the system, enforce the quality gates, and apply the strategic judgement that no prompt can replicate. That human-in-the-loop layer isn't optional overhead. It's what separates scalable content from scalable noise.
The ROI is real. But it's proportional to how deliberately you build.
So audit your current briefing process honestly. Map the data flow. Pick one architecture from this guide, no-code, low-code, or full-code, and ship a minimal viable pipeline against your next content sprint. The time you recover will tell you everything.
Frequently Asked Questions
Can you fully automate SEO content briefing?
No. Anyone selling you on full automation is selling you a problem you'll discover three months later when your rankings plateau.
The realistic split is roughly 80/20: automate the data-gathering, SERP analysis, structural scaffolding, and keyword mapping, then apply human judgement to the 20% that actually differentiates your content. The angle, the contrarian take, the proprietary insight that an LLM cannot invent. Skip that 20% and you end up with what I call beige content: technically complete, competitively indistinguishable, and quietly ignored by both readers and Google. The system handles the grunt work. A human decides what's worth saying.
What is the best AI content brief generator?
Honestly, there isn't one. The right answer depends entirely on your team's technical capability and your operational constraints.
For a non-technical marketing team that needs something working by Friday, a turnkey product like Frase or SEOBoost is the pragmatic choice: data integrations are pre-built and the learning curve is shallow. For a technical team that wants granular control over keyword filtering, prompt logic, and pipeline orchestration, a custom build using Claude or GPT-4o connected to the Ahrefs API via n8n is significantly more powerful and, at scale, more cost-effective. A middle path exists too: piping Semrush keyword data into a structured ChatGPT prompt and outputting to Notion via Zapier works well for teams sitting between those two extremes.
The comparison in Section 3 maps these options against team profile and budget, which is more useful framing than chasing a single "best" label.
Will Google penalise AI-generated content?
Google's official position, reiterated by John Mueller as recently as November 2025, is that its systems "don't care if content is created by AI or humans" , what they evaluate is whether the content is helpful. [Source: dataslayer.ai]
The practical risk isn't the AI origin. It's the quality outcome. SE Ranking's 16-month experiment, run across 20 new domains with 2,000 fully unedited AI articles, found that rankings collapsed around the three-month mark after an initial indexation spike: the content had no E-E-A-T signals, no unique insight, and no editorial refinement to sustain visibility. [Source: seranking.com] The same experiment showed that AI-drafted content with substantive human editing continued to perform well.
Google's March 2024 spam policy formalised this as "scaled content abuse." The target is low-value content published at volume to manipulate rankings, not AI as a production method. The QA checklist in Section 5 is what keeps your output on the right side of that line.
What are the biggest data risks when using AI for SEO briefs?
The primary risk is what I think of as the hallucination tax. LLMs will confidently fabricate keyword search volumes, invent competitor metrics, and misattribute statistics if you ask them to source their own data. This isn't a bug you can prompt your way out of , it's a structural limitation of how language models work.
The fix is architectural. The LLM's role in your pipeline should be to synthesise and structure data, never to source it. Keyword volumes, difficulty scores, search intent signals, and SERP composition must come from live data sources , Ahrefs, Semrush, DataForSEO, or Google Search Console , ingested upstream of the LLM call.
A secondary risk is data privacy: feeding client data, unreleased product details, or commercially sensitive information into a third-party LLM API without reviewing that provider's data retention policy is a legal exposure most teams don't think about until it's too late.
What's the main trade-off between a turnkey tool and a custom-built pipeline?
Speed of setup versus strategic control. And the economics flip at scale.
A turnkey suite like Frase or Clearscope gets you producing briefs within hours, but you're operating inside someone else's logic: their prompt structure, their data sources, their content scoring model. That's a black box, and it becomes a cost centre as your volume grows. A custom pipeline , built on n8n or a similar orchestration layer, pulling from the Ahrefs or DataForSEO API, and calling an LLM with your own prompt templates , has a higher upfront setup cost (days to weeks, not hours) but gives you complete control over every layer.
That control matters strategically. For sites with a Domain Rating under 40, a custom build lets you implement hard competitive filters that automatically exclude keywords where the SERP is dominated by DR 70+ domains , a targeting decision a turnkey tool won't make for you. Long-term, the per-brief cost of a custom pipeline is a fraction of a SaaS subscription at high volume.
How do you measure the success of an automated briefing system?
Measure it at two levels: pipeline efficiency and content performance.
On the pipeline side, the key metrics are time saved per brief (target: from 2+ hours manually to under 20 minutes automated), brief acceptance rate by your writers (if it's below 90%, your prompt engineering or QA gate needs work), and production velocity , expect a 3-5x increase in briefs produced per week with the same headcount. [Source: digitalapplied.com] On the content performance side, track organic traffic for auto-briefed articles versus your manual baseline at 30, 60, and 90 days post-publication; average content quality score pre-publication via Surfer or Clearscope; and keyword ranking movement for target terms.
The 90-day window matters. As the SE Ranking experiment demonstrated, short-term indexation gains can mask longer-term quality problems , you need enough runway to see whether the traffic actually holds. [Source: seranking.com]