April 21st, 2026
Duplicate Content SEO: How AI Tools Prevent and Resolve Issues
 WD
WDWarren Day
Semrush's 2024 study found duplicate content on 50% of analysed sites.
If you're managing a large website with thousands of pages, you're probably wasting crawl budget and confusing AI search systems with duplicated or semantically similar content. The manual approach to finding and fixing this stuff doesn't scale. Not for e-commerce platforms, not for media publishers, not for complex corporate sites.
You know the basics. Canonical tags, 301 redirects. But applying them systematically across a sprawling site is a completely different problem.
The real issue isn't some mythical duplicate content SEO penalty. It's the operational cost of detection, split rankings, and diluted authority in an era where AI search systems are doing the interpreting.
Fixing this in 2026 means moving past piecemeal fixes. You need a systematic, AI-enhanced workflow that detects semantic duplicates at scale, prioritises remediation by crawl budget impact and AI search visibility, and builds preventative checks into your development lifecycle before problems ship.
Here's what this article covers: how to choose embedding models and calibrate detection thresholds, how to build a prioritisation framework that focuses engineering effort where it actually matters, and how to automate checks in your CI/CD pipeline. Theory to operational reality. The goal is to stop wasting crawl budget and start sending clear signals to both traditional and AI search systems.
Understanding Duplicate Content: Beyond the 'Penalty' Myth
Here's a misconception worth clearing up. Google doesn't typically apply a manual penalty for unintentional duplicate content. Instead, it filters out near-identical pages from search results and picks a "canonical" version to show. The technical distinction matters to SEOs, but for your business the outcome is the same: pages that don't rank and traffic that never arrives.
The real damage happens in three areas, each wasting finite resources.
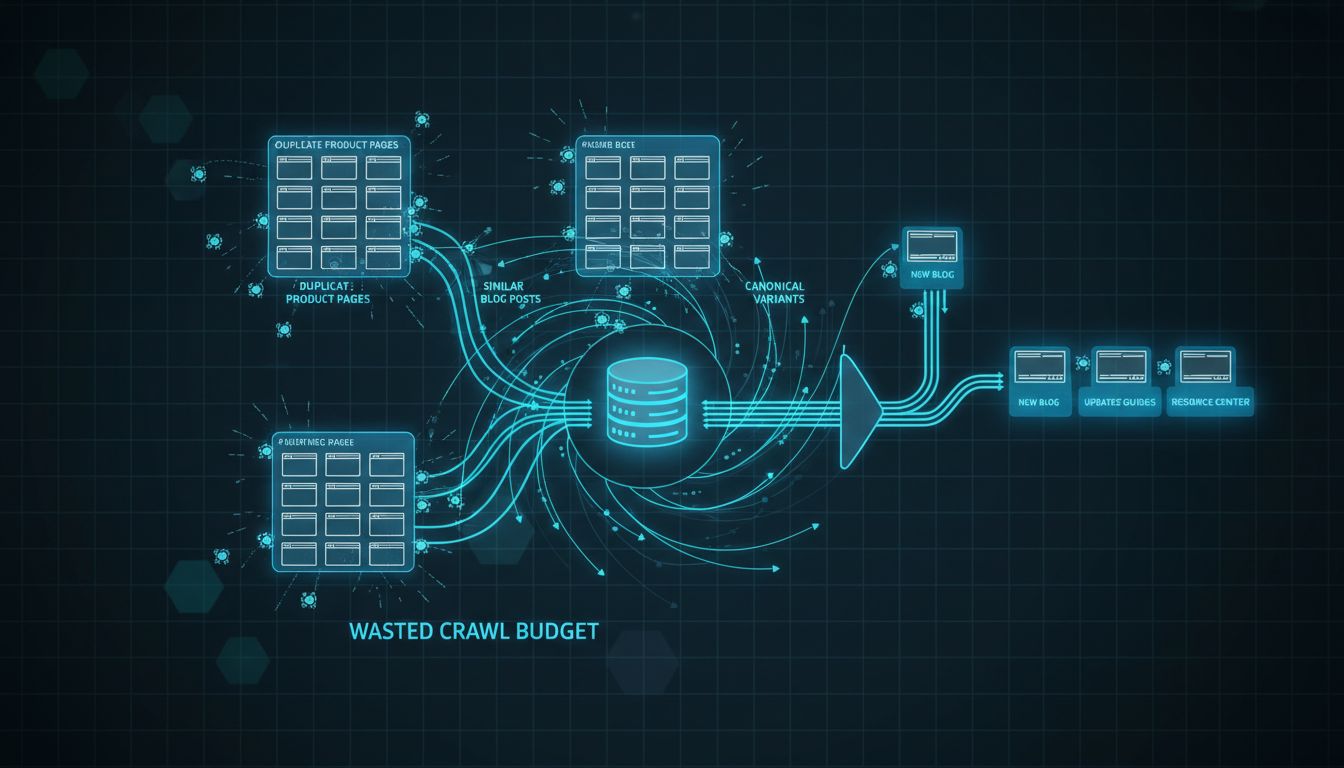
First, crawl budget. Googlebot allocates a limited number of pages it will crawl on your site within a given timeframe. When it spends cycles indexing ten near-identical product variations or five different URLs for the same article, that's time not spent discovering your new, unique content. Google's own guidance frames this as an efficiency problem, wasted crawls delay indexing of pages that actually deserve visibility [Source: https://developers.google.com/search/blog/2017/01/what-crawl-budget-means-for-googlebot].
Second, ranking dilution. Backlinks, engagement signals, and topical authority get split across multiple URLs. Instead of consolidating all equity onto one strong page, you fragment it. Think of it as dividing your marketing budget across five identical ad campaigns instead of funding one good one.
The business impact is real. Analysis shows sites with moderate duplication (20-30% of indexed pages) average a 10-15% organic traffic decline. For heavily duplicated sites (>50% of pages), that potential loss climbs to 25-40% [Source: https://ninestats.com/organic-traffic-loss-duplicate-content].
Third, and this is the newest problem for 2026, blurred intent signals for AI search. Systems like Google's Search Generative Experience (SGE) need to identify the definitive, most authoritative source on a topic. When your content is paraphrased across a blog post, a product page, and a help centre article, the AI can't easily tell which version actually represents your expertise. That confusion directly reduces your chances of being cited in AI-generated answers.
This is the core challenge for technical teams right now. The problem isn't exact copies, those are easy to find with MD5 hashing. It's semantic duplicates: pages where the wording differs but the core meaning and intent overlap significantly. These are the pages that waste engineering time, confuse search algorithms, and quietly drain your organic potential.
The goal for duplicate content SEO isn't just fixing copies. It's optimising your entire site's indexation efficiency and signal clarity for both traditional and AI-driven search.
How AI Detects Duplicate Content: From Hashes to Semantic Embeddings
Exact duplicates are easy. Run an MD5 hash on your page content and flag matching checksums. Done.
The hard part is semantic duplicates: pages that express the same intent with different wording, structure, or translation. That's where most SEO tools fall short, and where duplicate content SEO actually gets interesting.
Start with exact matches using MD5 or SHA hashes. These catch literal copies, identical product descriptions, boilerplate legal text, accidentally published drafts. Then move to near-exact methods like MinHash for shingled text comparison or Levenshtein distance for short fields like titles and meta descriptions. A Levenshtein threshold around 0.9 works well for spotting "Product X - Blue" versus "Product X – Blue".
The real breakthrough for scale is semantic embeddings. These convert text into high-dimensional vectors, mathematical representations where similar meanings sit close together in vector space. Cosine similarity between those vectors measures semantic overlap, not just shared words.
Two pages discussing "best running shoes for flat feet" and "top footwear for fallen arches" might share almost no vocabulary but score high semantic similarity. That's the point.
Choosing your embedding model matters. For English-only sites, all-mpnet-base-v2 performs well. If you're working across languages or comparing translated content, multilingual models like e5_base or BGE-M3 embed text from different languages into a shared vector space. e5_base (110M parameters) balances retrieval accuracy with low latency, around 11 milliseconds per query in benchmarks. Source: aimultiple.com
Here's the pipeline: extract clean text from each URL, pass it through your chosen embedding model, store the resulting vectors in a dedicated index. That's where FAISS (Facebook AI Similarity Search) becomes essential.
FAISS is an approximate nearest neighbour (ANN) index built for high-dimensional vectors. It runs fast similarity searches across millions of pages without comparing every pair individually. Without it, a 100,000-page site requires nearly 5 billion pairwise comparisons. That's not a pipeline, that's a problem.
Once indexed, run nearest-neighbour searches to find candidate duplicates, then apply clustering algorithms like DBSCAN to group semantically similar pages into manageable clusters for remediation. Embeddings + ANN + clustering is what powers enterprise-scale deduplication.
ByteDance's Volcano Engine used semantic thresholds between 0.86 and 0.95 to deduplicate over 20,000 support tickets daily, saving roughly 10 person-days of manual review. Source: aimultiple.com
The precision available now is pretty striking. GPTZero's detection system hit 98.6% accuracy and 97.2% recall in benchmarks, with a 0.0% false-positive rate for distinguishing AI-generated from human text. Source: gptzero.me Children's Medical Center Dallas reduced its duplicate record rate from 22% to 0.14% using AI-powered detection.
You don't need to build this from scratch. Screaming Frog's SEO Spider now integrates semantic analysis using LLM embeddings, flagging pages above configurable similarity thresholds. Sitebulb offers advanced testing beyond basic cosine similarity. For custom, programmatic workflows, especially inside CI/CD pipelines, you'll likely script your own using Hugging Face models, FAISS, and a clustering library.
The real shift is stopping thinking about "duplicate content" as identical text. It's pages competing for the same search intent, regardless of phrasing. That's what wastes crawl budget and confuses ranking algorithms. Your detection system needs to understand meaning, not just match strings.
Calibrating Your Detection: Finding the Right Similarity Thresholds
The biggest mistake you can make with AI-powered duplicate detection is assuming there's a universal similarity threshold.
Set it too low and your team drowns in false positives, pages flagged as duplicates that are just... similar. Set it too high and you miss genuine duplicates that are quietly splitting your crawl budget. The ranges vary a lot depending on the tool and what you're actually trying to catch.
Here's what real implementations look like:
| Tool/Use Case | Threshold Range | Notes |
|---|---|---|
| Screaming Frog (Semantic) | 0.4 (general) / 0.95 (high similarity) | Default values for LLM-based similarity scoring. |
| Screaming Frog (Near-Duplicate) | ~90% | Lexical similarity default for near-identical text. |
| ByteDance/Volcano Engine | 0.86–0.95 | Used to deduplicate 20,000+ support tickets. |
| Academic Study (Title Matching) | 0.9 | Levenshtein distance threshold for product titles. |
These aren't settings you copy and paste. They're starting points.
The ByteDance example is telling. They didn't use a default, they tuned their system for their specific content (support tickets) and saved roughly 10 person-days of manual review per day. Source: aimultiple.com
Your calibration process should be systematic:
- Build a Gold-Standard Dataset. Manually label 200-500 page pairs from your site. Tag them as "definite duplicate," "near-duplicate," or "unique." This is your ground truth.
- Run Detection at Multiple Thresholds. Process your dataset through your detection pipeline (embedding model + similarity scoring) using a range of thresholds, say, from 0.7 to 0.95 in 0.05 increments.
- Calculate Precision and Recall. For each threshold, calculate:
- Precision: Of all pages flagged as duplicates, what percentage were correct? (High precision means fewer false alarms for your team to review).
- Recall: Of all actual duplicates in your dataset, what percentage did you catch?
- Plot a PR Curve and Choose. Plot precision against recall. The curve shows the trade-off. The right threshold is wherever your operational capacity meets your risk tolerance, how many false positives your team can handle versus how many missed duplicates you can live with.
For a large e-commerce site, you might prioritise recall (catching everything) even if that means a bigger review queue. For a media site with thousands of articles, you probably want high precision so you're not accidentally merging distinct stories.
Content type matters more than people realise. Product descriptions for similar SKUs will naturally cluster at 0.9+. Blog posts covering the same news event might be semantically close but written from different angles, you'd need a lower threshold (0.75-0.85) to catch those without generating noise. One threshold for your whole site rarely makes sense if your content varies.
This isn't academic. Getting duplicate content SEO wrong has a real cost.
LinkGraph found a site where duplicate pages caused 5,000 wasted crawls, fixing it dropped crawl waste by 73%. Source: linkgraph.com Your threshold directly determines how efficiently you find and fix those leaks.
The AI-Enhanced Workflow: Prevent, Detect, and Resolve at Scale
Having calibrated thresholds is one thing. Making them operational is another.
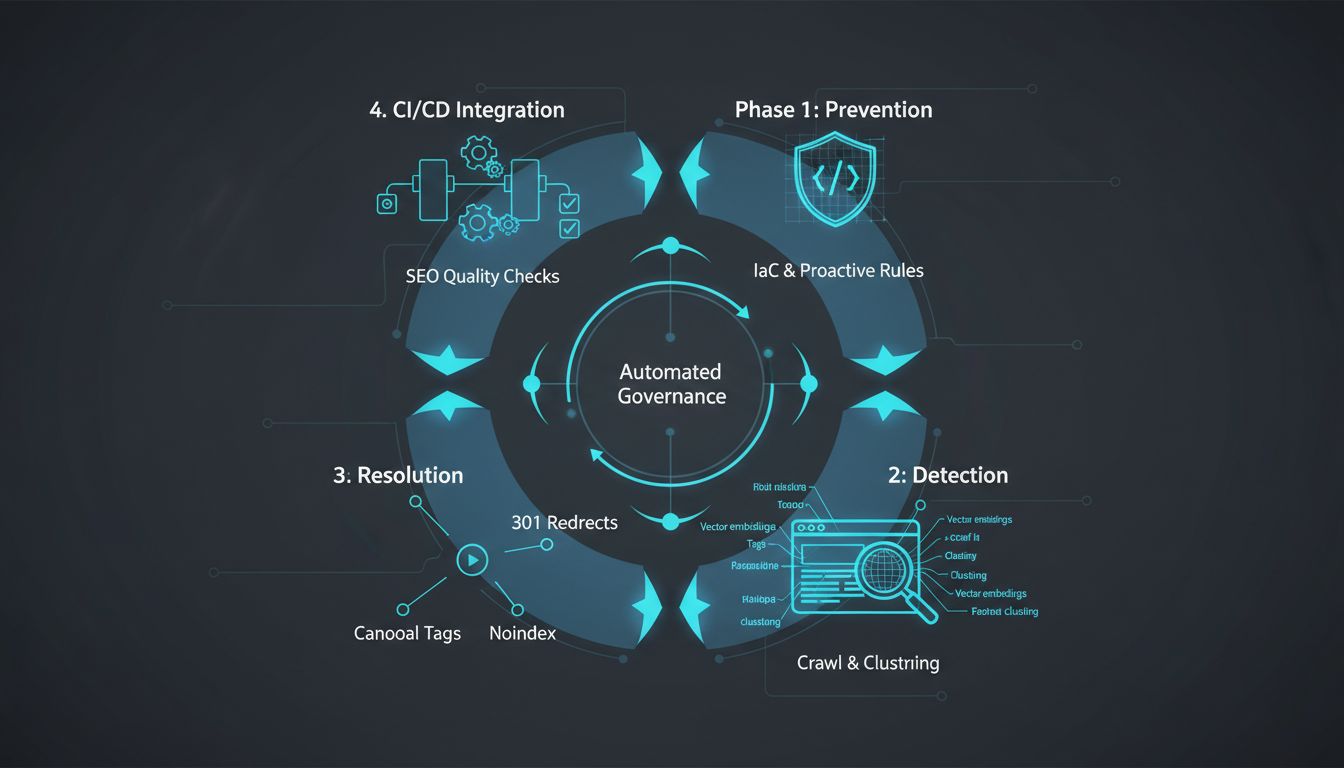
The difference between a theoretical solution and one that actually fixes your duplicate content SEO issues comes down to workflow design. You need a four-phase, cyclical system that moves from prevention through detection to resolution, with automated governance keeping the whole thing running.
This isn't about running a one-off audit. It's about building infrastructure that treats duplicate content as a quality defect in your software delivery pipeline.
Phase 1: Prevention (Infrastructure as Code for SEO)
Prevention is the highest-ROI activity. Every duplicate page you stop before it's created saves you the cost of detection, analysis, and remediation later.
I've seen this firsthand across agency and in-house roles: the engineering teams that treat SEO as a quality attribute bake these rules into their systems from day one.
Start by enforcing URL standards as code. Your CMS or routing layer should have immutable rules for case sensitivity, trailing slashes, and parameter handling. Use robots.txt with Disallow directives for known problematic parameters (like session IDs or sort orders) and submit parameter handling rules in Google Search Console. The goal is to ensure only one canonical version of any logical page can be requested.
Next, mandate self-referencing canonical tags on every single page. This is non-negotiable.
The most common engineering pitfall I encounter is a CMS generating the tag with a relative URL or the wrong protocol (HTTP vs HTTPS). Your canonical tag must be an absolute URL, and it must point to the exact page being viewed. Implement this as a middleware or template component that cannot be overridden without explicit technical review.
Finally, implement redirect management logic. Use a centralised redirect map (a YAML or JSON file in version control) rather than ad-hoc .htaccess or plugin rules.
This lets you programmatically check for chains (URL A → URL B → URL C) and loops before they hit production. A redirect chain of just two hops can waste 30% of the crawl budget for those pages.
Phase 2: Systematic Detection
With prevention in place, you schedule systematic detection. For most teams, this means regular site-wide crawls using tools like Screaming Frog configured with multi-method detection, exact hashes for literal copies, near-duplicate analysis for 90%+ similarity, and semantic embeddings for paraphrased content.
For custom pipelines at scale (10,000+ pages), you'll implement something like this:
- Crawl & Extract: Use a headless browser or SSR output to get the fully rendered text, stripping navigation and boilerplate.
- Embed: Run the clean text through a model like
all-mpnet-base-v2ore5_baseto generate vector embeddings. - Index & Search: Load embeddings into a FAISS index for fast approximate nearest neighbour (ANN) similarity search.
- Cluster: Apply DBSCAN clustering on the results to group near-duplicates, which reduces thousands of pairwise comparisons into manageable clusters.
The output isn't just a list of similar pages. It's a prioritised report of duplicate clusters with their similarity scores and suggested canonical URLs.
That structure is what makes batch remediation possible. The Pedowitz Group's AI-enhanced workflow, which reduced manual review time from 3-8 hours to 8-20 minutes, operates on this clustered output principle. Source: pedowitzgroup.com
Phase 3: Prioritised Resolution
You'll never fix all duplicates at once. Prioritisation is critical. Sort your clusters by business impact:
- Crawl Budget Wasters: Pages with high crawl depth but low commercial value (old tag archives, filtered views with no unique content). Pure efficiency drains.
- Backlink Equity Splitters: Pages with incoming external links where authority is divided across multiple URLs. Consolidating these has an immediate ranking impact.
- Key Landing Page Duplicates: Your main product or service pages that have semantic duplicates, like a blog post summarising a service that now competes with the main service page.
Apply the correct resolution tool for each case:
- 301 Redirect: Use this for retired pages that should permanently move. It's a directive, link equity and traffic are passed.
- Canonical Tag: Use this for active variants you need to keep (print versions, sorted/filtered views). It's a strong signal pointing to your preferred version.
- Noindex: Reserve this for truly internal or utility pages you must keep live but don't want in search indices.
Track resolutions in batches (e.g., "Q1 Redirect Batch - Product Filters") and monitor Google Search Console for indexation changes. Expect a 2-4 week lag for consolidation to show up in search results.
Phase 4: CI/CD Integration (Automated Governance)
This is where you close the loop. Integrate duplicate content checks into your CI/CD pipeline and SEO stops being a periodic, reactive audit, it becomes a proactive quality gate.
Here's a practical workflow you can implement this week:
- Pre-commit / PR Checks: Run a script against new or modified HTML/JSX templates that validates the presence and correctness of self-referencing canonical tags. Fail the build if they're missing or malformed.
- Staging Deployment Checks: After deploying to staging, run a lightweight automated crawl (Puppeteer or Playwright) focused on new URL patterns introduced by the release. Flag any new parameter variations or unintended redirect chains.
- Production Deployment Gate: Make passing the canonical tag check and a clean staging crawl report a requirement for merging to your main branch.
This aligns directly with Google's guidance on managing crawl budget through technical discipline. Source: developers.google.com
It also mirrors the automation patterns used for code quality, security scanning, and performance budgets. Failing a build for missing canonical tags means you're treating duplicate content risk with the same seriousness as a broken test or a security vulnerability.
The result is a self-reinforcing system. Prevention reduces the volume of new duplicates. Systematic detection finds what slips through. Prioritised resolution fixes the high-impact issues. And CI/CD integration makes sure future work doesn't regress everything you've fixed.
That's how you stop fighting duplicate content and start governing it.
Why Duplicate Content Blurs Signals for AI Search (And How to Fix It)
Traditional search engines had a simple problem with duplicate content SEO: wasted crawl budget, split ranking signals. AI search engines like Google AI Overviews and Microsoft Copilot have a harder problem. These systems don't just rank pages, they need to find authoritative "grounding sources" to cite in generated answers. When your content exists across multiple URLs, you're forcing the AI to guess which version actually represents your expertise.
Bing's December 2025 guidance says this directly: duplicate content "blurs intent signals" and reduces your chances of being selected as a grounding source [https://blogs.bing.com/webmaster/December-2025/Does-Duplicate-Content-Hurt-SEO-and-AI-Search-Visibility]. The system clusters similar pages and picks one representative URL.
If your preferred page isn't clearly dominant, you might lose visibility entirely.
This isn't theoretical. The Shopify case study showed 275% traffic growth after duplicate content cleanup, with the improvement directly tied to increased Google AI Overview visibility [https://seo-f1rst.com/case-studies/shopify-seo-275-traffic-growth-google-ai-overview-visibility/]. When you consolidate, you're making it easier for AI systems to identify and cite your authority.
Fixing this comes down to four signals:
-
Consolidated backlink equity: Use 301 redirects to funnel all external links to your single canonical URL. Every backlink to a duplicate page is a vote for the wrong candidate.
-
Dominant internal linking: Make sure your preferred version gets 3-5x more internal links than any duplicates. That's the clearest signal you can send about which page matters.
-
Consistent structured data: Implement schema markup (Product, Article, FAQ) on your canonical page only. Duplicate structured data creates conflicting signals about which page represents the entity.
-
Freshness signals: Regularly update your canonical page with new information, while leaving duplicates static. AI systems prioritize recently updated content when selecting grounding sources.
None of this is new. These are classic SEO best practices, the stakes are just higher now. Where traditional search might split rankings between duplicates, AI search might ignore your content entirely if it can't find a clear authoritative source.

Duplicate content remediation is no longer just about crawl efficiency. It's a prerequisite for AI search visibility. When you fix duplicates, you're creating a clear signal path for AI systems to recognize and cite your expertise.
Common Pitfalls & What to Avoid in Your Workflow
Most of these failures aren't subtle, they're just easy to skip when you're moving fast.
Don't treat canonical tags as an afterthought. A self-referencing canonical on every page is non-negotiable. The real problem shows up with chain canonicals (Page A points to B, B points to C) or relative URLs, both create broken signals that search engines quietly ignore. Moz's guidance on this is definitive for a reason.
Relying on a single detection method is where a lot of duplicate content SEO work falls apart. MD5 hashes catch exact copies and nothing else. You need layers: exact hashes for identical pages, Levenshtein distance for titles, semantic embeddings for paraphrased content. Screaming Frog's multi-technique approach exists because no single method is enough.
Hardcoded similarity thresholds will also get you. Teams copy ByteDance's 0.86-0.95 range or Screaming Frog's 0.4 default, run it on their content, and wonder why the results are useless. You have to calibrate against your own data. Product descriptions need different settings than blog posts.
The crawl budget issue is subtle but expensive. Leaving low-value duplicate pages indexable means Googlebot spends time on them instead of finding your new content. That directly delays indexation of pages that could actually drive revenue. LinkGraph's case study found a 73% reduction in crawl waste after fixing this, that's measurable.
Finally, over-relying on AI-generated content creates a new version of the same problem. Run hundreds of product descriptions through the same prompt and you get pages that are technically unique but semantically identical. Google's September 2025 spam update specifically targeted this "industrially processed" content. Treat AI output as a first draft, then add the details only your team actually knows.
These aren't just SEO mistakes. They're system design failures, and the fix is building validation into your workflow before things break, not after.
Conclusion
Duplicate content SEO in 2026 isn't a checklist item. It's a systems problem, and it needs a systems solution.
That means combining hashes, lexical distance, and semantic embeddings, with thresholds calibrated to your actual content types and business goals. Not someone else's defaults. Yours.
The goal is simple: protect your crawl budget and send clean signals to both traditional and AI search systems. Fragmented authority directly hurts visibility, and that's a fixable problem.
Long-term, this only works if prevention is baked into your CI/CD pipeline. Audits are a starting point, not a finish line.
Start with a multi-method scan. Map out remediation by business impact, not just similarity scores. Fix the duplicates that waste crawl resources or split ranking signals first.
Then work with your engineering team to get the simplest check into your next deployment cycle. Canonical tag validation is the obvious first step.
Build the system. Don't just run the audit.
Frequently Asked Questions
Is having duplicate content an issue for SEO?
Yes. Duplicate content forces search engines to filter out redundant pages, which wastes crawl budget and splits ranking signals across URLs. In the AI search era, it's worse, multiple similar pages blur intent signals, and you're less likely to be picked as the authoritative source for AI-generated answers.
How much duplicate content is acceptable?
"Acceptable" is the wrong frame. It's about managed risk, not a safe threshold. Semrush's 2024 study found duplicate content on 50% of analysed sites, and Ninestats research shows sites with 20-30% duplication average a 10-15% organic traffic decline.
The practical move is to prioritise by impact. Fix the duplicates wasting crawl budget or splitting high-value backlink equity first, not whatever gets you to some arbitrary percentage.
Will AI replace SEO?
No. It's transforming it. The work is shifting from manual audits to building and managing AI-augmented workflows, things like using embeddings for semantic duplicate detection at scale.
SEO professionals who get comfortable with those tools will be more valuable, not less. They'll be solving harder problems, like making intent clear for AI search systems.
What is the most common fix for duplicate content?
The canonical tag. But it's a suggestion, not a command, search engines can ignore it. If you're actually consolidating or retiring duplicate pages, a 301 redirect is the real fix. It permanently transfers link equity and user traffic to the one URL that matters.
Is SEO dead or evolving in 2026?
Evolving, fast. AI search creates new challenges around intent clarity, while also giving you better tools, like embedding models for semantic duplicate detection. The fundamentals haven't gone anywhere. Understanding what users want and delivering something worth finding still matters. The technical implementation is just getting more complex.
What is the 80/20 rule for SEO?
In duplicate content remediation, 80% of the benefit comes from fixing the 20% of duplicates with the highest impact. That means parameter-heavy e-commerce URLs burning crawl budget, or pages splitting backlink equity you actually care about.
Trying to eliminate every minor duplication across thousands of pages is how you spend six months and move nothing.