April 12th, 2026
Automated Internal Linking: A Strategic Guide for SEO and AI Crawlers
 WD
WDWarren Day
You've published 500 new blog posts this quarter. Your developers are drowning in Jira tickets requesting "just add a link from this new article to the pricing page." Your site's crawl budget is hemorrhaging on faceted navigation filters while your cornerstone content sits three clicks deep, invisible to Googlebot. This isn't an SEO problem, it's a data infrastructure failure. And automated internal linking is the fix most engineering teams haven't properly architected yet.
The standard response is a plugin, a spreadsheet, or a content editor with a checklist. None of those scale. What actually scales is treating your internal link graph as a first-class data system, one deliberately designed to feed contextual signals to both traditional search crawlers and the new generation of AI citation models like PerplexityBot and Claude.
The stakes are real. GAME, the UK retailer, increased pages crawled by Google to 82% and grew organic revenue 146% year-over-year after restructuring internal linking as a deliberate system rather than an editorial afterthought.
This guide is a phased engineering blueprint, from audit to production deployment. I'll cover what data inputs your system actually needs, how to evaluate tooling (including Link Whisper) against your specific stack, how to set data-driven linking rules that don't require human sign-off on every new page, and how to measure impact on crawl efficiency, indexation, and rankings.
No checklists. No vague best practices. Just the system.
Why Manual Internal Linking Is a Broken Model for Scale
Internal linking is the programmatic creation of contextual relationships between your site's pages to optimise crawl budget, PageRank flow, and semantic signals. Unlike external linking, internal links are entirely within your control. That's precisely why neglecting them at scale is an engineering failure, not just an SEO oversight.
The manual approach made sense when your site had 50 pages. A content editor could scan existing articles, spot a relevant mention, and add a link. But that workflow doesn't survive contact with a growing content operation. It's reactive by nature: someone publishes a new page, and a link only gets added if someone remembers. Most of the time, they don't.
The numbers are stark. InLinks analysed 5,112 websites and found that 82% of internal linking opportunities were missed before any optimisation was applied. That's not a marginal inefficiency. In one of their case studies, adding 92 internal links to a single article moved it from position 18 to position 8 in Google. Those opportunities existed the entire time. Nobody connected the dots.
There's also a second audience problem manual processes completely ignore. Your internal link graph now serves two distinct consumers: Googlebot, which follows links to discover and index pages, and AI crawlers like PerplexityBot and Claude's web reader, which traverse your link structure to extract contextual signals for citation and answer generation. These aren't identical requirements. Googlebot prioritises crawl efficiency and PageRank flow; AI crawlers prioritise semantic coherence and topical clustering. A manually patched link structure is optimised for neither.
Most teams don't notice manual internal linking is broken until they're already hundreds of pages deep and the compounding cost has become invisible.
The core objectives: more than just 'link juice'
Most teams frame internal linking as a PageRank distribution problem. Get authority from your homepage, pass it down to your money pages, done. That framing isn't wrong, it's just incomplete, and in 2026 it leaves two significant performance levers untouched.
Your automated internal linking system should serve three distinct, measurable objectives at once.
Objective 1: Crawl budget optimisation
Googlebot has a finite crawl budget for your site. Waste it on orphaned pages, redirect chains, and content buried five clicks from the homepage, and your most valuable URLs simply don't get indexed in time to matter.
The GAME case study is the clearest proof point I've seen. By restructuring internal links to reduce click depth and surface priority product pages, they lifted the percentage of pages crawled by Google from 18.4% to 82%, a 64-point jump, directly before Black Friday. Organic revenue grew 146% year-over-year as a result.
KPIs to track: crawl coverage %, orphan page count, average inlinks per page, crawl depth distribution.
Objective 2: Topical authority and semantic signalling
Search engines don't just follow links, they read them. The anchor text, the source page context, and the cluster of pages linking to a target all contribute to how confidently Google associates that URL with a topic.
IFTTT's 33% year-over-year organic traffic growth came specifically from treating internal linking as a topical authority mechanism, not just a crawl aid. Pillar-cluster architectures work because they create a dense, coherent signal around a subject, not because they funnel PageRank.
KPIs to track: impressions and average position for cluster keywords, pages per session within topic clusters.
Objective 3: AI citation likelihood
This is the objective most teams aren't measuring yet, which makes it the biggest competitive gap right now.
Perplexity, Claude, and Google's AI Overviews don't scrape random pages, they select sources. A well-linked topical cluster signals credibility to these systems: multiple pages reinforcing the same entities and concepts, with clear navigational hierarchy between them. That's the structure an AI model needs to confidently cite you rather than a competitor.
Topical authority explains 17% of AI citation variance. Domain authority explains less than 4%. Your internal link graph is the primary mechanism for demonstrating topical authority at scale.
KPIs to track: brand mentions in AI-generated answers (trackable via tools like Profound or manual query sampling), citation frequency across Perplexity and AI Overviews.
These three objectives compound on each other. Better crawl coverage means more pages indexed, which means more topical signals available, which means stronger citation candidacy. But only if you're engineering for all three from the start, tools like Link Whisper exist precisely because maintaining that structure manually doesn't scale.
The Data Stack: What You Need to Automate Intelligently
Automation is only as good as the data feeding it. Before you write a single line of linking logic, you need four inputs wired together. Miss any one of them and you're optimising blind.
1. Full site crawl This is your node map. Tools like Screaming Frog or Sitebulb walk every URL on your site and return the current link graph: which pages exist, how they connect, what's orphaned, and how many clicks deep each URL sits from the homepage. Without this, you don't know the shape of the problem you're solving.
2. Server logs
Logs are where the truth lives, and most teams skip them entirely. GSC shows you a sanitised, delayed view of what Google chose to report. Logs show you what Googlebot actually did, second by second, on your server. If Googlebot is spending 40% of its crawl cycles on /filter-by-colour=blue parameter URLs, that budget is being incinerated on pages that will never rank. You won't see that in GSC. You'll only see it in the raw access logs.
For large sites, this data is non-negotiable. Parse your logs with the ELK stack, Screaming Frog Log Analyser, or Botify's log ingestion pipeline. Segment by bot type, URL pattern, and HTTP status code. What you find will often be alarming.
3. Google Search Console GSC gives you the demand signal: which queries your pages are already impressioning for, which URLs are indexed versus discovered-but-not-indexed, and where click-through rate is underperforming. This is how you identify pages that deserve more internal equity, they have GSC impressions but weak rankings, meaning they're visible to Google but not being surfaced confidently.
4. Analytics and CRM data GA4 and your CRM tell you which pages actually convert. A page with 200 monthly organic sessions but a 12% conversion rate deserves more internal links than a page with 5,000 sessions and a 0.2% rate. Engagement data, scroll depth, time on page, exit rate, also signals whether a page is worth linking to or just linking from.
The integration goal is a unified dataset where you can join crawl frequency from logs with GSC impression volume and GA4 conversion rate. That join query is what tells you which pages are being under-served by your current link graph and should be prioritised for incoming links. Tools like automated internal linking platforms and Link Whisper build parts of this picture automatically, but they still need clean inputs to surface useful suggestions.
One honest caveat: if your site has fewer than 50 pages, you don't need this full stack. A crawl export and GSC's Coverage report will get you most of the way there. The complexity should match the scale, building a data pipeline for a 40-page site is engineering theatre.
Choosing Your Automation Engine: A Technical Comparison
Before picking a tool, ground this in context. Internal linking is a technical SEO problem, and like most technical SEO problems, the right solution depends on your constraints: site scale, CMS, team capacity, and how much governance overhead you can absorb.
Here's the decision framework I'd use before evaluating any vendor:
- WordPress, 50–2,000 pages → Plugin-based engines
- Content-rich, platform-agnostic, 2,000–50,000 pages → Semantic/NLP engines
- Enterprise, 50,000+ pages, multiple subdomains → Log-based platform engines
Plugin-Based Engines (e.g., Link Whisper)
These are the fastest path from zero to automated internal linking if you're on WordPress. Link Whisper scans your content, surfaces orphan posts, and generates link suggestions directly inside the editor. Setup takes minutes.
The trade-off is in the matching logic. Most plugin-based engines rely on keyword co-occurrence rather than semantic similarity, they find a phrase in one post and suggest linking it to another post where that phrase appears. That works fine for obvious connections but misses subtler topical relationships. Suggestions also need manual QA; the tool doesn't know your content hierarchy, so it will occasionally recommend links that are technically relevant but contextually odd.
Semantic/NLP Engines (e.g., InLinks, Quattr)
These operate differently at the core. Rather than matching keywords, they build vector representations of your content and connect pages based on conceptual proximity. Quattr uses embeddings and pulls GSC signals to identify which pages need link equity most. InLinks works through entity recognition, mapping named entities across your content graph and building links where those entities appear in context.
The results can be significant. InLinks' own analysis across 60,000+ target pages found that 82% of internal linking opportunities were being missed before automation, a finding that holds up across industries. Where these tools can fall short is in respecting explicit content hierarchies. If you have a strict parent-child taxonomy, you'll likely need to configure silo rules manually rather than trusting the semantic model to infer them.
Log-Based Platform Engines (e.g., Botify SmartLink)
This tier is a different category of investment. These platforms ingest server logs, GSC data, analytics, and full crawl outputs to build a prioritised picture of which pages need links, which source pages have authority to give, and where crawl budget is being wasted. Botify's SmartLink can export recommendations as CSVs or deploy changes directly via PageWorkers, no developer required for execution, but significant configuration required upfront.
The GAME case study shows what this looks like at scale: after implementing structured internal linking through Botify, 82% of their pages were being crawled by Google, and revenue from organic traffic grew 146% year-over-year. That's not a plugin result. That's what happens when you feed a platform real operational data and let it optimise at depth.
The core trade-off across all three tiers is this: the more automated the deployment, the greater the need for upfront rule sophistication and ongoing monitoring. A plugin adding 50 links per day with loose matching rules will eventually create noise in your link graph. An enterprise platform deploying at scale with misconfigured priorities can systematically push authority in the wrong direction. Automation amplifies both good decisions and bad ones.
The System in Action: A Phased Implementation Blueprint
The previous section covered tool selection. This one is about execution, the exact sequence of steps to build an automated internal linking system that doesn't fall apart six months in.
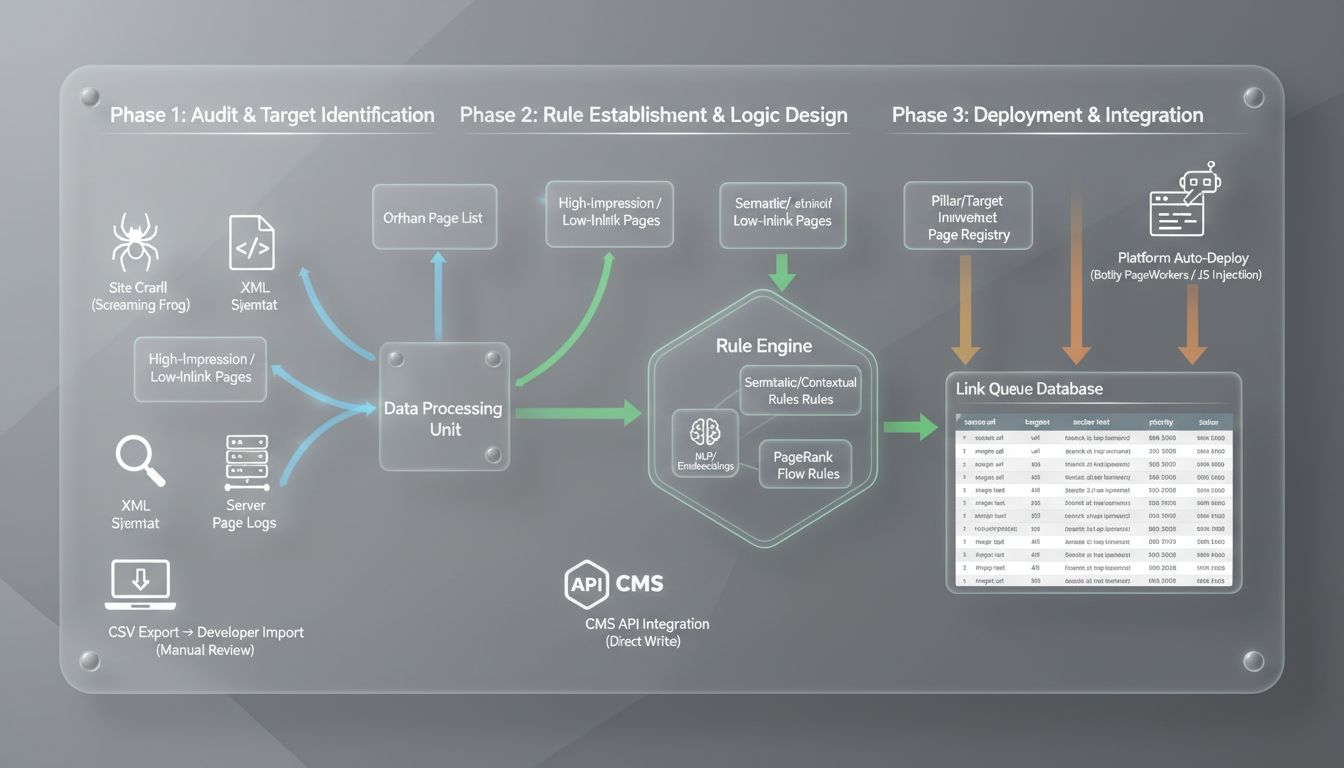
Phase 1: Audit & target identification
Before you automate anything, get a clear picture of your current link graph. Run a full site crawl (Screaming Frog, Sitebulb, or Botify) and cross-reference the output with three other data sources: your XML sitemap, Google Search Console performance data, and server logs if you have them.
From that combined dataset, produce four outputs:
- Orphan page list, URLs with zero internal inlinks from crawlable pages. These are your most urgent targets. 41% of sites have no internal links pointing to their target pages, which means this list is almost always longer than anyone expects.
- High-impression / low-inlink pages, Pull GSC data filtered for pages with >500 monthly impressions and fewer than 5 internal inlinks. These pages already have topical relevance in Google's eyes; they just lack structural support.
- Redirect chain inventory, Any internal link pointing to a 301 URL is wasting equity. Map every chain and flag the final destination URL.
- Pillar/target page registry, A prioritised list of the pages you want to rank. This becomes your link equity destination map.
Phase 2: Rule establishment & logic design
This is where most implementations go wrong. Teams jump to deployment without defining what a "good link" actually means in their system. You need three distinct rule types:
1. Hierarchical/Taxonomic rules, Structural, deterministic. Every product page links to its parent category. Every blog post in a cluster links to the pillar. These are non-negotiable and should be enforced programmatically.
2. Semantic/Contextual rules, Probabilistic, based on content similarity. A TF-IDF or embedding-based match between source and target content. This is where tools like Quattr (vector embeddings) or a custom Python script using BERT earn their place.
3. PageRank flow rules, Directional. High-traffic pages with strong external backlink profiles should link to deeper, commercially important pages that need equity. Pull your top 20% of pages by organic sessions and treat them as equity distributors.
Here's a simplified CSV structure for your link queue, the format I use when exporting to a developer for CMS import:
source_url,target_url,anchor_text,rule_type,priority,status
/blog/seo-audit-guide,/services/technical-seo,technical SEO audit,hierarchical,1,pending
/blog/keyword-research-tools,/blog/long-tail-keywords,long-tail keyword strategy,semantic,2,pending
/blog/content-marketing-roi,/services/content-strategy,content strategy,pagerank_flow,1,pending
The rule_type and priority columns matter for governance. You need to know why a link was placed when you audit it in six months.
Insider workflow note: By feeding keyword clustering data from an API like Ahrefs into your rule logic, you can create a closed-loop system that automatically links newly published content to the relevant pillar. When Spectre publishes a new article, it queries the Ahrefs API for the target keyword's parent cluster, identifies the pillar URL, and adds the hierarchical link before the post goes live. Zero manual intervention.
Phase 3: Deployment & integration
Three deployment patterns, in order of operational risk:
- CSV export → developer import, Lowest risk. A human reviews the queue before anything touches production. Slower, but appropriate for the first deployment.
- CMS API integration, Your linking logic writes directly to post metadata or content fields via API. Suitable once your rules have been validated.
- Platform auto-deploy, Tools like Botify PageWorkers or InLinks' JavaScript injection handle deployment automatically. Highest velocity, highest governance requirement.
Always deploy to staging first. Run a crawl of the staging environment and verify the link graph looks as intended before pushing to production. This sounds obvious. It's routinely skipped.
Phase 4: Monitoring & governance
Set up a KPI dashboard tracking the following on a weekly cadence:
| Metric | Tool | Target Direction |
|---|---|---|
| Crawl coverage % | Botify / GSC Coverage report | ↑ |
| Orphan page count | Screaming Frog / Semrush | ↓ |
| Average inlinks per page | Crawl export | ↑ |
| Organic CTR for targeted pages | GSC | ↑ |
| Pages indexed / submitted ratio | GSC | ↑ |
Set automated alerts for two conditions: any page that was previously linked dropping back to zero inlinks (content updates can silently break links), and any new orphan pages created by publishing workflows.
The governance rule I enforce on every project: no page goes live without at least two contextual internal links already pointing to it. That single constraint eliminates the orphan page problem at source.
Optimising for the new audience: AI crawlers (Perplexity, Claude)
The governance rule above keeps orphan pages out of your system. But there's a second audience your internal linking strategy now has to serve, one that doesn't care about PageRank at all.
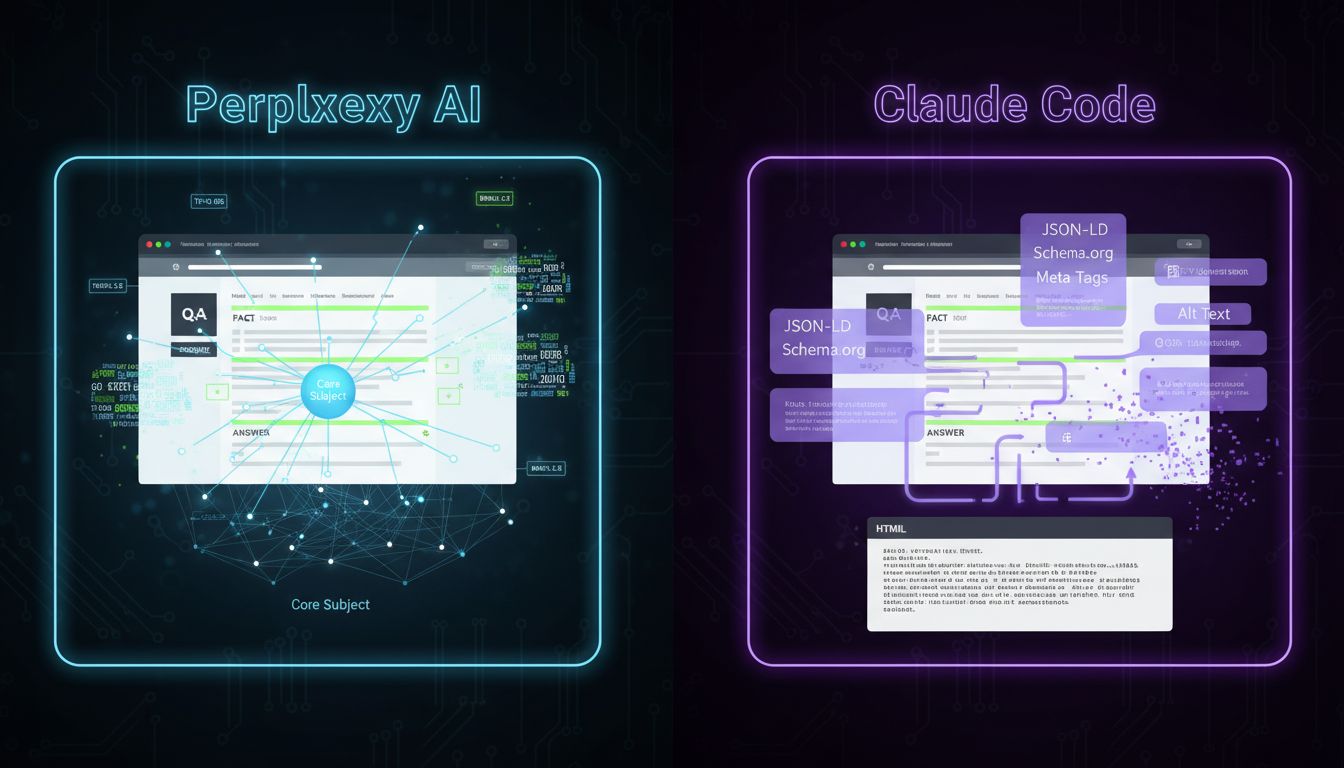
AI search engines use links differently. Perplexity doesn't crawl your site to distribute authority; it crawls to find citation-worthy content. Whether your page gets surfaced as a source in an AI-generated answer depends on how clearly your content signals topical expertise, and your internal linking architecture feeds directly into that signal.
The mechanics matter, and they vary by platform. Perplexity fetches pages live via on-demand crawling, combining BM25 lexical search with vector embeddings to rank passages for answer extraction. It rewards Q&A-formatted content, factual statements, and sites that demonstrate depth across a topic, not just a single well-written article. Claude Code, by contrast, runs your HTML through a Turndown conversion that strips JSON-LD, schema markup, meta descriptions, and image alt-text entirely before the model ever sees your content. If you're investing heavily in structured data without also embedding that information in clean body copy, you have a genuine blind spot.
Three things worth prioritising given these behaviours:
Put critical claims in rendered HTML, not just schema. If the answer to a question lives only in a JSON-LD block, Claude won't see it. Write it into the prose.
Use FAQ and Q&A schema as a supplement, not a substitute. Perplexity does index schema when it crawls directly, and it actively favours question-based headings. Use them, just don't rely on them exclusively.
Build dense topical clusters through internal linking. A single well-linked article is a candidate. A cluster of five interlinked articles covering a topic from multiple angles signals authoritative coverage. That's what tips Perplexity's authority scoring in your favour. A semantically relevant internal link from a high-authority page within a cluster doesn't just pass equity, it adds relational context that an AI model can use to understand your site's depth on a subject. Tools like Link Whisper can surface these cluster-building opportunities automatically, which is where automated internal linking starts pulling real weight beyond traditional SEO.
For monitoring, track your AI citation footprint manually by querying Perplexity and ChatGPT for your target topics, or use tools like Profound or Otterly.ai to automate brand mention tracking across AI answer engines.
What not to do: the quickest ways to break your system
You can build a technically sound automated internal linking system and still destroy its effectiveness through a handful of predictable mistakes. These aren't edge cases, I've seen every one of them in production.
Over-optimised anchor text
Repeating the same exact-match keyword phrase across dozens of internal links is a spam signal, not a ranking strategy. It also collapses topical nuance, Google reads variation in anchor text as evidence of genuine contextual relevance. Use descriptive, natural phrases that reflect the destination page's actual content.
Uncontrolled faceted navigation
Faceted filters (size, colour, brand, price range) can generate thousands of indexable URL combinations, each with internal links pointing at them. This fragments your link equity across pages that have no ranking value and burns crawl budget on content Google never needed to index. Fix it: apply canonical tags pointing to the main category page, use nofollow on filter links, and make sure breadcrumb links are clean HTML pointing to canonical URLs.
Linking through redirects
Every 301 or 302 in your internal link chain wastes crawl budget and leaks equity. SearchPilot's case study data confirms that pointing links directly to final destination URLs improves both crawl efficiency and user experience. Audit your internal links for redirect targets quarterly.
JavaScript-rendered links for critical navigation
HTML links are discovered immediately. JS-rendered links require a second-pass render, which means slower discovery and potential indexation delays. If a link matters for crawling, it belongs in the initial HTML response.
Full automation without guardrails
Accepting every Link Whisper suggestion without review leads to irrelevant, low-confidence links that dilute topical authority. Set hard limits: no more than three links to a single target from one page, minimum relevance score thresholds, and mandatory human review for anything touching your top commercial URLs.
Indiscriminate internal nofollow
Internal nofollow links still consume crawl budget. They don't pass equity, but they do attract crawler attention. Reserve nofollow for pages that genuinely shouldn't be indexed, login pages, PPC landing pages, thank-you pages, not as a catch-all for links you're uncertain about.
Conclusion
automated internal linking isn't something you set up once and walk away from. It's a data infrastructure system that needs the right inputs, the right engine for your scale, and ongoing governance to stay effective.
The results are real. A 146% YoY revenue increase at GAME. A 33% organic traffic lift at IFTTT. A 9.5k weekly visitor gain worth $150k annually. [Source: seoclarity.net, uproer.com] That's what happens when internal linking is treated as a system rather than a checklist item.
The fundamentals don't change with scale: clean crawl paths, semantically relevant anchors, zero orphan pages, a link graph that surfaces your best content in the fewest clicks. What changes is the tooling and the data pipeline behind it.
One thing worth keeping in mind for 2026: your audience isn't just Googlebot anymore. Perplexity, Claude, and their successors are reading your site too. Structure it so they can.
Start with a crawl. Screaming Frog or Sitebulb will expose your orphan pages and inlink distribution in under an hour. Then pick one method from this guide, a link whisper pilot, a semantic clustering run, or a full Botify deployment, and build from there. The first deployment tells you everything you need to scale the rest.